")
")
")
")
")
")
")
")
Zusammenstellung aller Tutorials von René Passiers Blog:
.
Die Tutorials behandeln diverse Themen zu den Bereichen Haiku, Scripting und yab.
Da sich viele der Tutorials auf vorherige Tutorials beziehen, auch Bereichsübergreifend, sind diese in der Reihenfolge zusammengestellt, wie diese auf dem Blog erschienen sind.
Ein Menü erleichtert die Übersicht der einzelnen Tutorials. Diese sind Bereichsbezogen aufgebaut:
- So findet man unter yab alle yab Tutorials
- unter Scripting alle Scripting und Shell Tool Tutorials
- unter Haiku alle System Tipps und Tutorials
- und unter Test sind Softwaretests zu finden
Vielen Dank an René Passier, der uns erlaubt hat seine Tutorials auf der BeSly zu veröffentlichen.
Haiku - Grafiktreiber und Bilschirmauflösung
Dienstag, 11. Oktober 2011
Seit einiger Zeit verwende ich nun bereits die Haiku- Version "Alpha 3" und ärgere mich, obwohl diese wirklich sehr stabil läuft, das sich der Vesa- Treiber nicht davon überzeugen läßt, die volle Auflösung von 1600 x 900 auf meinem Notebook darzustellen. Dies kann jedoch durch einen kleinen Trick geändert werden. So habe ich festgestellt, daß z.B. in der Haiku- Version "42795" andere "Graphic- Accelerants" enthalten sind als in der Haiku- Version "Alpha 3". Zu finden sind diese unter:
| /boot/system/add-ons/accelerants |
Der "vesa.accelerant", welcher von meinem System verwendet wird, ist in der Haiku- Version "42795" um einiges größer als in der Haiku- Version "Alpha 3". Also habe ich den neueren Treiber einfach über den "alten" kopiert. Nach einem Neustart konnte ich feststellen das weitere Auflösungen zur Verfügung stehen, unter Anderen auch die von mir benötigte 1600 x 900. Diese also schnell ausgewählt und siehe da, volle Auflösung und ein schönes klares Bild. Jetzt macht das Arbeiten mit Haiku gleich wieder viel mehr Spaß.
zurück zur Übersicht
Scripting - Grafiktreiber ermitteln
Donnerstag, 13. Oktober 2011
So, nachdem ich nun den Grafiktreiber, in Sachen, Auflösung erfolgreich ausgetrickst habe, stellt sich noch die Frage, wie bin ich eigentlich darauf gekommen, das mein System den "vesa.accellerant" verwendet und nicht irgendeinen Anderen
Also habe ich eine entsprechende Frage im Haiku- Forum gestellt und recht schnell eine Antwort, mit dem Verweis auf die FAQ's, bekommen.
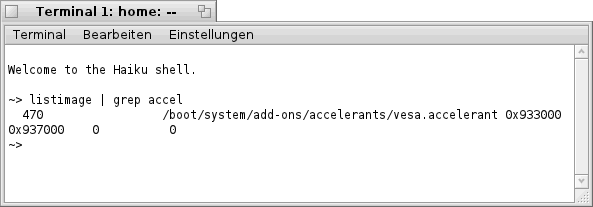
Das Zauberwort heißt in diesem Fall "listimage", und damit die Ausgabe nicht zu lang wird, filtern wir diese mit "grep accel". In der ausgegebenen Zeile läßt sich dann der aktuell geladene Grafik- Treiber ablesen. In diesem Beispiel ist es der "vesa.accelerant".
yab - Grafiktreiber ermitteln
Freitag, 14. Oktober 2011
Nachdem ich im letzten Post den Weg zum Ermitteln des aktuell geladenen Grafiktreibers beschrieben habe, folgt nun die entsprechende Umsetzung für yab.
Der Quellcode sollte sich dabei von selbst erklären, ist relativ einfach gehalten und wurde bewußt als Sub- Routine entwickelt. Damit ist es möglich den Quellcode universell einzusetzen.
Der Aufruf der Subroutine erfolgt folgendermaßen:
| print "aktuell geladener Grafiktreiber: " + Upper$(_GetGraphicAccelerant$()) |
| export sub _GetGraphicAccelerant$() // Variablen definieren local SystemInput$ local NumberOfTokens local Help$ dim Line$(1) dim Position$(1) // den Befehl "LISTIMAGE | grep accel" ausführen und Ausgabe // in SystemInput$ speichern SystemInput$ = system$("listimage | grep accel") // SystemInput$ in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInput$, Line$(), "\n") // die entsprechende Zeile weiter zerlegen ... NumberOfTokens = split(Line$(1), Position$(), "/") Help$ = Position$(6) // ... um den gewünschten Eintrag zu finden NumberOfTokens = split(Help$, Position$(), ". ") return Position$(1) end sub |
Scripting - Bildschirmeinstellungen ändern
Mittwoch, 19. Oktober 2011
Wie sicherlich allen bekannt sein dürfte, lassen sich die EInstellungen für den Bildschirm (Auflösung, Bildwiederholfrequenz, etc.) recht komfortabel über "Preferences / Screen" ändern.
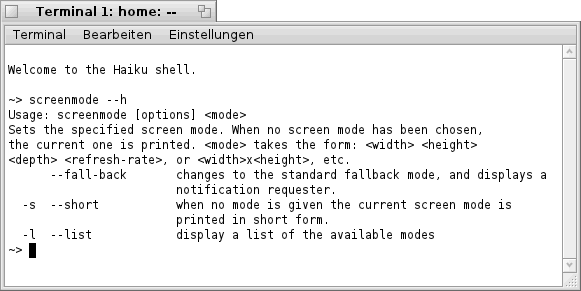
Was aber möglicherweise nicht so vielen bekannt sein dürfte ist, dass man dies auch über das "Terminal" erledigen kann. Für diesen Zweck steht das kleine Programm "screenmode" im "Terminal" zur Verfügung. Beim Aufruf des Programms "screenmode" mit der Option "--h" erhält man folgende Ausgabe.
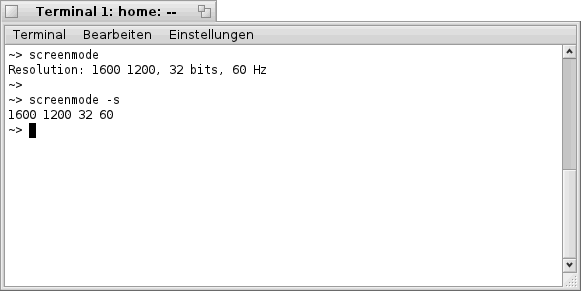
Beim Aufruf von "screenmode" oder "screenmode -s" (gibt eine Kurzform ohne Bezeichnung und Trennzeichen aus) erhält man Informationen zu den momentan eingestellten Werten, wobei die Bedeutung der Werte Folgende ist:
- Wert1 = horizontale Bildschirmaulösung
- Wert2 = vertikale Bildschirmauflösung
- Wert3 = Farbtiefe in Bit per Pixel
- Wert4 = Bildwiederholfrequenz
Beim Aufruf des Programms "screenmode" mit dem optionalen Parameter "-l" erhält man eine Liste mit allen verfügbaren Bildschirmmodi. Die Liste sieht dabei in etwa so aus:
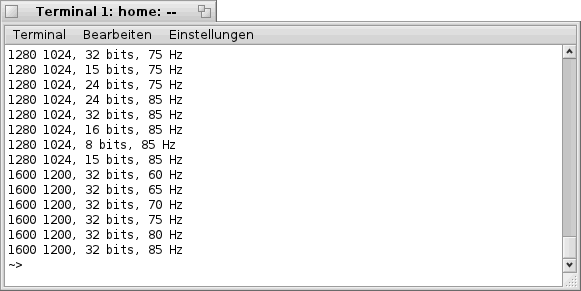
Kombiniert man nun den Befehl "screenmode" mit dem Inhalt einer der ausgegebenen Zeilen, ändern sich die Auflösung, Farbtiefe, etc. sofort und ohne Rückfrage.
Beispiel:
| screenmode 1600 1200, 32 bits, 60 Hz |
 |
Wählt man eine Einstellung mit zu hoher Bildwiederholfrequenz, kann dies in einem schwarzen Bildschirm münden. |
yab - DropBox
Donnerstag, 3. November 2011
Bei meinen letzten Experimenten mit der "DropBox" ist mir aufgefallen, das die Dokumentation hierzu ein wenig unvollständig ist. Deshalb möchte ich an dieser Stelle eine kleine Korrektur/Erweiterung aufzeigen.
In der Dokumentation ist zu lesen, dass der Befehl:
| Item$ = DROPBOX GET$ DropBox$, Position |
Den Eintrag an der angegebenen "Position" liefert. Dies ist prinzipiell auch richtig. Es stellt sich allerdings die Frage woher weis man denn die Position? Folgendes Beispiel soll dies veranschaulichen.
| Position = DROPBOX GET DropBox$ |
Gibt die Position des aktuell in der DropBox ausgewählten Wertes zurück (gezählt wird in diesem Fall ab 0).
| Item$ = DROPBOX GET$ DropBox$, Position |
Gibt den Wert (z.B. den String) der aktuell in der "DropBox" ausgewählten Position zurück (gegebenen Fall muss zu "Position" 1 addiert werden).
 |
Zu beachten ist an dieser Stelle die Verwendung von "DROPBOX GET" und "DROPBOX GET$". |
yab - Bildschirm- Modus ändern
Montag, 7. November 2011
Nachdem ich vor kurzem aufgezeigt habe wie sich die Haiku- Bildschirm- Einstellungen per Kommando- Zeile ändern lassen, folgt nun eine Möglichkeit der Umsetzung in yab. Im Folgenden handelt es sich um ein kleines Beispiel- Programm welches als Anregung und Inspiration zu verstehen ist. Aus diesem Grund habe ich auch auf Sicherheitsabfragen verzichtet.
Das Beispiel- Programm, welches ich mit vielen Kommentaren versehen habe, sollte sich dabei ebenfalls von selbst erklären. Als Grundgerüst habe ich das "Basic Template" von yab 1.5 verwendet.
| #!/boot/home/config/bin/yab doc MiniScreenModeGUI doc doc Beispiel- Programm zum Ändern des Bildschirm- Modus doc aus eigenen yab- Programmen. doc doc Arien Speers, 11/2011 // set DEBUG = 1 to print out all messages on the console DEBUG = 0 // Nimmt die Liste aller verfügbaren Bildschirm- Modi auf Resolution$ = _GetScreenResolutionList$() // Programm- Fenster öffnen OpenWindow() // Main Message Loop dim msg$(1) while(not leavingLoop) nCommands = token(message$, msg$(), "|") for everyCommand = 1 to nCommands if(DEBUG and msg$(everyCommand)<>"") print msg$(everyCommand) switch(msg$(everyCommand)) case "_QuitRequested": case "MainWindow:_QuitRequested": leavingLoop = true break // Ändern des Bildschirm- Modus auf Button- Klick case "MyButton": _ChangeResolution() break default: break end switch next everyCommand wend // Fenster wieder schließen CloseWindow() end // Setup the main window here sub OpenWindow() // Variablen- Definitionen local NumberOfTokens dim Line$(1) // Fenster öffnen window open 100,100 to 490,200, "MainWindow", "MiniScreenModeGUI" // eine DropBox erstellen dropbox 20, 20 to 370, 1, "MyDropBox", "Auflösung wählen", "MainWindow" // einen Button erstellen button 20, 60 to 370, 1, "MyButton", "Änderungen übernehmen", "MainWindow" // enthält die Anzahl der verfügbaren Bildschirm- Modi (Zeilen) NumberOfTokens = split(Resolution$, Line$(), "\n") // alle Bildschirm- Modi zur DropBox hinzufügen for i = 1 to NumberOfTokens dropbox add "MyDropBox", Line$(i) next i return end sub // Close down the main window sub CloseWindow() // Fenster wieder schließen window close "MainWindow" return end sub // Erstellt eine Liste aller verfügbaren Bildschirm- Modi sub _GetScreenResolutionList$() // Variablen- Definition local SystemInput$ // fürht den Befehl "screenmode -l" aus um die die Liste // der verfügbaren Bildschirm- Modi zu erhalten SystemInput$ = system$("screenmode -l") // gibt das Ergebnis zurück return SystemInput$ end sub // Ändert den Bildschirm- Modus je nach gewählten Einstellungen sub _ChangeResolution() // Variablen- Definition local Position // ermittelt die aktuelle Position des gewählten Eintrages // innerhalb der DropBox Position = dropbox get "MyDropBox" // wenn Position = 0, dann nichts unternehmen if Position <> 0 then // setzt den Bildschirm- Modus wie in der DropBox ausgewählt system("screenmode " + dropbox get$ "MyDropBox", Position + 1) endif end sub |
|
Wählt man eine Einstellung mit zu hoher Bildwiederholfrequenz, kann dies in einem schwarzen Bildschirm münden |
yab - Bildschirm- Modus ändern - Update
Dienstag, 8. November 2011
Wie ich soeben bemerkt habe, hat sich das Programm "screenmode" in den aktuelleren Haiku- Versionen etwas geändert. So sind zwei neue Optionen (-q und -m) hinzugekommen. Außerdem hat sich das Verhalten von "screenmode" ebenfalls etwas geändert.
So wartet das Programm nun 10 Sekunden auf eine Bestätigung der Änderungen, erfolgt diese nicht, schaltet es wieder in den ursprünglichen Bildschirm- Modus zurück.
Um dies von yab aus zu umgehen kann aber der Schalter "-q" verwendet werden. Dieser sorgt dafür, dass die Änderungen wieder ohne Bestätigung übernommen werden. Für das Beispiel- Programm aus dem letzten Post bedeutet dies eine kleine Änderung am Quellcode, die wie folgt aussieht.
Folgende Zeile, zu finden in der Sub- Routine "_ChangeResolution()", im Quell- Code muss dazu ausgetauscht ...
| system("screenmode " + dropbox get$ "MyDropBox", Position + 1) |
... und durch diese ersetzt werden
| system("screenmode -q " + dropbox get$ "MyDropBox", Position + 1) |
Scripting - Grafik- Karte(n) ermittelne
Montag, 14. November 2011
Nachdem ich in den letzten Wochen aufgezeigt habe wie man z.B. die Bildschirm- Einstellungen per Kommandozeile ändern kann, oder den aktuellen Grafik- Treiber ermittelt, möchte ich Euch heute zeigen wie man die, vom System, erkannte(n) Grafik- Karte(n) ermittelt.
Zu diesem Zweck benötigen wir wieder ein Terminal und den Befehl "listdev". Der Befehl "listdev" gibt dabei Auskunft über alle gefundenen Devices, so auch über die Grafik- Karte(n).
Folgender Screenshot soll dies einmal verdeutlichen (die markierten Einträge sind dabei von Interesse).
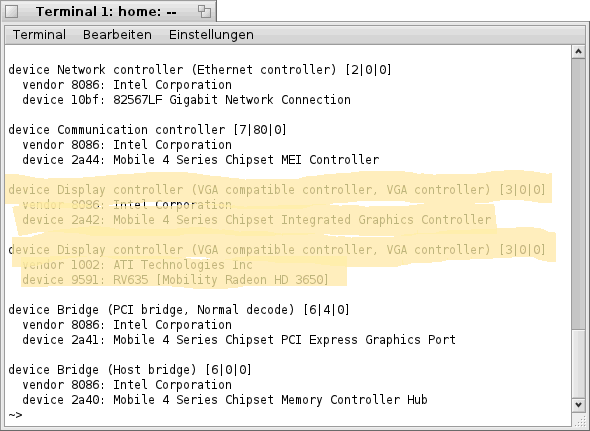
Wie also zu erkennen ist, befinden sich in meinem Notebook gleich zwei Grafik- Adapter, ein Intel "Mobile 4 Series Chipset Integrated Graphics Controller" und eine ATI "Radeon HD 3650 HD".
Mit dem Befehl "listdev" lassen sich natürlich noch viele weitere Informationen herausfinden, doch dazu später mehr.
zurück zur Übersicht
yab - Grafik- Karte(n) ermitteln
Donnerstag, 17. November 2011
Wie ich in meinem letzten Post bereits geschrieben habe läßt sich mit dem Befehl "listdev", unter Anderem, herausfinden welche Grafik- Karte(n) im System verbaut bzw. von Haiku erkannt werden. Natürlich läßt sich dies auch mit yab, Dank dem "system$"- Befehl, ebenfalls bewerkstelligen.
Der untenstehende Quelltext sollte ausreichend mit Kommentaren versehen sein, sodaß die prinzipielle Arbeitsweise nachvollzogen werden kann. Im Prinzip ist das ja auch nicht wirklich schwer. Die Informationen mit dem "system$"- Befehl holen und dann ein wenig mit den Strings jonglieren, é voilà, schon hat man das gewünschte Ergebnis.
Der Aufruf der "sub"- Routine erfolgt z.B. in der Form
| print _GetGraphicCard$() |
Als Ergebnis wird dann z.B. folgendes zurückgeliefert
| Intel Corporation / Mobile 4 Series Chipset Integrated Graphics Controller ATI Technologies Inc / RV635 [Mobility Radeon HD 3650] |
Da yab leider keine Arrays aus "sub"- Routinen zurückgeben kann, außer man definiert sie bereits im Hauptprogramm, habe ich mich entschieden, einen durch "CR" geteilten String zurück zu geben. Dies trifft aber auch nur dann zu, wenn mehr als eine Grafik- Karte im System vorhanden ist bzw. gefunden wird.
| export sub _GetGraphicCard$() // lokale Variablen definieren local SystemInput$ local NumberOfTokens local NumberOfDummyTokens local ArrayCounter local SearchString local Result$ dim Line$(1) dim Dummy$(1) dim InfoArray$(1) SearchString$ = "device Display controller" ArrayCounter = 1 Result$ = "" // den Befehl "listdev" auf der Kommandozeile und das Ergebnis // in SystemInput$ speichern SystemInput$ = system$("listdev") // den Text in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInput$, Line$(), "\n") // innerhalb der ermittelten Zeilen den gewünschten String suchen // und alle Informationen im Array InfoArray$ speichern for i = 1 to NumberOfTokens if (instr(Line$(i), SearchString$)) then // Vendor- Name ermitteln NumberOfDummyTokens = split(trim$(Line$(i + 1)), Dummy$(), " :") for k = 4 to NumberOfDummyTokens InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + Dummy$(k) + " " next k // Trennzeichen zwischen Vendor- und Device- Namen einfügen InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + " / " // Device- Name ermitteln NumberOfDummyTokens = split(trim$(Line$(i + 2)), Dummy$(), " :") for k = 4 to NumberOfDummyTokens InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + Dummy$(k) + " " next k ArrayCounter = ArrayCounter + 1 Redim InfoArray$(ArrayCounter) endif next i // Informationen in einen durch "\n" (CR) getrennten String schreiben // und als Ergebnis zurückliefern for i = 1 to arraysize(InfoArray$(), 1) - 1 Result$ = Result$ + InfoArray$(i) + "\n" next i return Result$ end sub |
yab - Netzwerk- Karte(n) ermitteln
Dienstag, 22. November 2011
Wie ich bereits im letzten Post beschrieben habe, ist es, dem "system$"- Befehl sei Dank, nicht besonders schwer/kompliziert entsprechende Informationen aus dem Haiku- System auszulesen. Somit war es relativ einfach die Bezeichnungen der Grafik- Karte(n) auszulesen.
Heute möchte ich zeigen, wie mit einer kleinen Änderung auch die Namen der Netzwerk- Karten angezeigt werden können. Dem/der Programm/Sub- Routine wird dabei lediglich ein neuer Name gegeben und der Such- String (Variable "SearchString$") wird dafür entsprechend angepaßt.
Aufgerufen wird die Routine nun wie folgt ...
| print _GetNetworkCard$() |
... und als Ergebnis erhält man z.B.
| Intel Corporation / 82545EM Gigabit Ethernet Controller (Copper) |
| export sub _GetNetworkCard$() // lokale Variablen definieren local SystemInput$ local NumberOfTokens local NumberOfDummyTokens local ArrayCounter local SearchString local Result$ dim Line$(1) dim Dummy$(1) dim InfoArray$(1) SearchString$ = "device Network controller" ArrayCounter = 1 Result$ = "" // den Befehl "listdev" auf der Kommandozeile und das Ergebnis // in SystemInput$ speichern SystemInput$ = system$("listdev") // den Text in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInput$, Line$(), "\n") // innerhalb der ermittelten Zeilen den gewünschten String suchen // und alle Informationen im Array InfoArray$ speichern for i = 1 to NumberOfTokens if (instr(Line$(i), SearchString$)) then // Vendor- Name ermitteln NumberOfDummyTokens = split(trim$(Line$(i + 1)), Dummy$(), " :") for k = 4 to NumberOfDummyTokens InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + Dummy$(k) + " " next k // Trennzeichen zwischen Vendor- und Device- Namen einfügen InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + " / " // Device- Name ermitteln NumberOfDummyTokens = split(trim$(Line$(i + 2)), Dummy$(), " :") for k = 4 to NumberOfDummyTokens InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + Dummy$(k) + " " next k ArrayCounter = ArrayCounter + 1 Redim InfoArray$(ArrayCounter) endif next i // Informationen in einen durch "\n" (CR) getrennten String schreiben // und als Ergebnis zurückliefern for i = 1 to arraysize(InfoArray$(), 1) - 1 Result$ = Result$ + InfoArray$(i) + "\n" next i return Result$ end sub |
yab - Sound- Karte(n) ermitteln
Freitag, 25. November 2011
So, dies soll das letzte Beispiel zum Ermitteln von System- Informationen mit Hilfe des "listdev"- Befehls sein. Alle, und es gibt noch einige, weiteren Informationen lassen sich, wie beschrieben, durch Änderung der Variable "SearchString$" abfragen. So ist es durchaus denkbar "Serial Bus Controller", "Storage Controller", "Bridge's" usw. abzufragen und die gewünschten Informationen zu erhalten.
In diesem Beispiel zeigen wir nun den/die Namen der Multimedia- / Sound- Karte an. Um dies zu erreichen benennen wir das/die Programm/Sub- Routine wieder um und ändern den "SearchString" entsprechend ab.
Der Aufruf der Routine erfolgt dann wieder z.B. so ...
| print _GetSoundCard$() |
... und als Ergebnis erhalten wir z.B.
| Intel Corporation / 82801AA AC'97 Audio Controller |
| export sub _GetSoundCard$() // lokale Variablen definieren local SystemInput$ local NumberOfTokens local NumberOfDummyTokens local ArrayCounter local SearchString local Result$ dim Line$(1) dim Dummy$(1) dim InfoArray$(1) SearchString$ = "device Multimedia controller" ArrayCounter = 1 Result$ = "" // den Befehl "listdev" auf der Kommandozeile und das Ergebnis // in SystemInput$ speichern SystemInput$ = system$("listdev") // den Text in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInput$, Line$(), "\n") // innerhalb der ermittelten Zeilen den gewünschten String suchen // und alle Informationen im Array InfoArray$ speichern for i = 1 to NumberOfTokens if (instr(Line$(i), SearchString$)) then // Vendor- Name ermitteln NumberOfDummyTokens = split(trim$(Line$(i + 1)), Dummy$(), " :") for k = 4 to NumberOfDummyTokens InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + Dummy$(k) + " " next k // Trennzeichen zwischen Vendor- und Device- Namen einfügen InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + " / " // Device- Name ermitteln NumberOfDummyTokens = split(trim$(Line$(i + 2)), Dummy$(), " :") for k = 4 to NumberOfDummyTokens InfoArray$(ArrayCounter) = InfoArray$(ArrayCounter) + Dummy$(k) + " " next k ArrayCounter = ArrayCounter + 1 Redim InfoArray$(ArrayCounter) endif next i // Informationen in einen durch "\n" (CR) getrennten String schreiben // und als Ergebnis zurückliefern for i = 1 to arraysize(InfoArray$(), 1) - 1 Result$ = Result$ + InfoArray$(i) + "\n" next i return Result$ end sub |
Scripting - "sysinfo" mit Schwächen
Mittwoch, 30. November 2011
Vor einiger Zeit habe ich, in der "yab - Programmierhilfe" auf der BeSly, eine Routine gefunden mit welcher es möglich ist die Größe des Arbeitsspeichers zu ermitteln. Keine Angst, die Routine ist völlig in Ordnung. Jedoch ist mir aufgefallen, das die Abfrage per "sysinfo -mem" nicht unter jeder Hardware- Konstellation korrekte Ergebnisse liefert (siehe Bild unten). So habe ich dies auf einem "Lenovo ThinkPad T500", eine virtuelle Maschine unter VirtualBox und ein "Sony Vaio VPCEA1C5E" getestet und auf dem Vaio funktioniert es nicht.
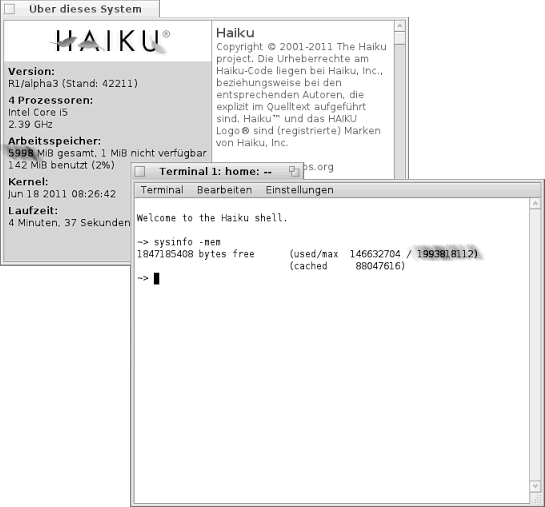
Wie im Bild zu sehen ist, erkennt Haiku den Arbeitsspeicher prinzipiell richtig, lediglich die Ausgabe per "sysinfo -mem" scheint nicht 100%ig korrekt zu arbeiten.
Aber auch dies stellt kein größeres Problem dar, da man die Größe des Arbeitsspeichers auch auf einem anderen Weg vom System erfragen kann. Dieser Weg heißt "vmstat". Per "vmstat" bekommt man die richtige Größe des Arbeitsspeichers, in Byte, und noch ein paar andere, interessante Dinge angezeigt (siehe Bild unten).
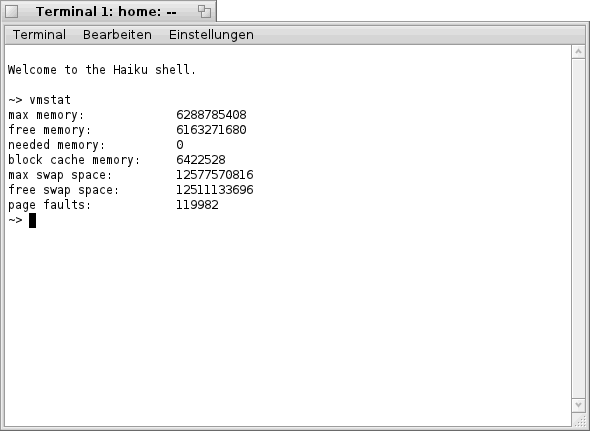
yab - Größe des Arbeitsspeichers ermitteln
Sonntag, 4. Dezember 2011
Anschließend am meinen letzten Beitrag "Haiku - "sysinfo" mit Schwächen", möchte ich Euch heute einen weiteren Weg zeigen, die Größe des Arbeitsspeichers zu ermitteln. Wie bereits erwähnt verwende ich dafür den Befehl "vmstat". Die untenstehende Sub- Routine ist dabei recht einfach gehalten und erklärt sich an Hand der beigefügten Kommentare von selbst.
Der Aufruf der Sub- Routine erfolgt z.B. so
| print _GetMemoryTotal() |
| export sub _GetMemoryTotal() // Variablen- Definition local NumberOfTokens dim Line$(1) // den Befehl "vmstat" ausführen und Ergebnis in Line$() speichern NumberOfTokens = split(system$("vmstat"), Line$(), ":\n") // in Zahl umwandeln und zurückgeben return val(trim$(Line$(2))) end sub |
yab - Größe des freien Arbeitsspeichers ermitteln
Montag, 12. Dezember 2011
Nachdem ich Euch bereits eine Alternative zum Auslesen der Größe des Arbeitsspeichers gezeigt habe, möchte ich Euch nun auch noch eine Alternative zeigen, wie man die Größe des noch freien Arbeitsspeichers ermitteln kann. Dazu nutzen wir ebenfalls wieder den Befehl "vmstat". Das untenstehende Beispiel soll dies verdeutlichen.
Der Aufruf des Sub- Routine erfolgt z.B. so
| print _GetMemoryFree() |
| export sub _GetMemoryFree() // Variablen- Definition local NumberOfTokens dim Line$(1) // den Befehl "vmstat" ausführen und Ergebnis in Line$() speichern NumberOfTokens = split(system$("vmstat"), Line$(), ":\n") // in Zahl umwandeln und zurückgeben return val(trim$(Line$(4))) end sub |
yab - Anzahl der Prozessoren/Kerne ermitteln
Freitag, 16. Dezember 2011
Wie Ihr wahrscheinlich auf der BeSly gelesen habt, kann man mit yab und dem Befehlszeilen- Programm "sysinfo" die Anzahl der Prozessoren bzw. Kerne auslesen. Es gibt aber auch noch eine andere Möglichkeit diese Information zu bekommen. Mit Hilfe des Befehlszeilen- Programms "nproc" ist es ebenfalls möglich die Anzahl der Prozessoren bzw. Kerne in Erfahrung zu bringen. Das untenstehende Beispiel zeigt Euch den prinzipiellen Weg.
Der Aufruf der Sub- Routine erfolgt z.B. so
| print _GetProcessorCount() |
| export sub _GetProcessorCount() // Variablen- Definition local NumberOfTokens dim Line$(1) // den Befehl "vmstat" ausführen und Ergebnis in Line$() speichern NumberOfTokens = split(system$("nproc"), Line$(), "\n") // in Zahl umwandeln und zurückgeben return val(trim$(Line$(1))) end sub |
yab - Datum einer Datei ermitteln
Freitag, 23. Dezember 2011
Nach dem ganzen Hardware- Informationen- Auslesen- Prozedere mal ein wenig Abwechslung, und so möchte ich Euch heute einen Weg zeigen, wie an das Datum einer Datei, mit yab, ermitteln kann. Auch in diesem Fall hilft uns wieder die Kommandozeile, und zwar mit dem Befehl "ls", weiter. Der Befehl "ls" hat, wie die meisten sicher wissen, eine ganze Menge Optionen und Schalter. Der von uns benötigte ist in diesem Beispiel "--full-time".
Die untenstehende Sub- Routine liefert das Ergebnis in der Form "Jahr-Monat-Tag", da Das Betriebssystem dies so zurückliefert. In einer erweiterten Version der Sub- Routine könnte man dies sicherlich ändern und auch das Trennzeichen könnte ausgetauscht werden. Dazu werde ich mir eventuell später mal Gedanken machen.
Der Aufruf der Sub- Routine erfolgt dann z.B. wieder in der Form, dabei wird vorausgesetzt, daß das Programm "GetFileDate.yab" auf dem Desktop abgelegt wurde.
| print _GetFileDate$("/boot/home/Desktop/GetFileDate.yab") |
| export sub _GetFileDate$(Filename$) // Variablen definieren local SystemInput$ local NumberOfTokens local Result$ dim Position$(1) // prüfen ob die angegebene Datei existiert if (not system("test -e " + Filename$)) then // den Befehl "LS --full-time" ausführen und Ausgabe in // SystemInput$ speichern SystemInput$ = system$("ls --full-time " + Filename$) // SystemInput$ in die einzelnen Bestandteile zerlegen NumberOfTokens = split(SystemInput$, Position$(), " .") // an Position 6 (Datum) steht die gewünschten Informationen Result$ = trim$(Position$(6)) else // wenn die angegebene Datei nicht gefunden wurde Result$ = "file not found" endif // Ergebnis zurückgeben return Result$ end sub |
yab - Uhrzeit einer Datei ermitteln
Montag, 26. Dezember 2011
Analog zu meinem Beitrag "yab - Datum einer Datei ermitteln" möchte ich Euch diesmal zeigen wie man auch die Uhrzeit einer Datei Datei per "yab" ermitteln kann. Das/die Programm/Sub- Routine ist dabei fast völlig identisch, wir verwenden nur einen anderen Wert, welchen wir bereits schon ermittelt haben.
Auch in diesem Beispiel läßt sich noch vieles verbessern (z.B. das Trennzeichen) aber auch dazu vielleicht später mehr.
Als Parameter wird ebenfalls wieder der Name der gewünschten Datei übergeben und der Aufruf erfolgt dann wieder so.
| print _GetFileTime$("/boot/home/Desktop/GetFileTime.yab") |
| export sub _GetFileTime$(Filename$) // Variablen definieren local SystemInput$ local NumberOfTokens local Result$ dim Position$(1) // prüfen ob die angegebene Datei existiert if (not system("test -e " + Filename$)) then // den Befehl "LS --full-time" ausführen und Ausgabe in // SystemInput$ speichern SystemInput$ = system$("ls --full-time " + Filename$) // SystemInput$ in die einzelnen Bestandteile zerlegen NumberOfTokens = split(SystemInput$, Position$(), " .") // an Position 6 (Datum) und 7 (Uhrzeit) stehen die // gewünschten Informationen Result$ = trim$(Position$(7)) else // wenn die angegebene Datei nicht gefunden wurde Result$ = "file not found" endif // Ergebnis zurückgeben return Result$ end sub |
In beiden Sub- Routinen wird auch überprüft ob die angegebene Datei überhaupt vorhanden ist, sollte dies nicht der Fall sein, wird als Ergebnis "file not found" zurückgegeben, ansonsten das Datum bzw. die Uhrzeit der angegebenen Datei.
zurück zur Übersicht
Scripting - "ifconfig" und das drahtlose Netzwerk
Mittwoch, 4. Januar 2012
Wie die Meisten sicherlich bereits wissen, kann man mit Hilfe des Kommandozeilen- Befehls "ifconfig" einem drahtlosen Netzwerk beitreten. Voraussetzung dafür ist jedoch mindestens die Haiku- Version 42775 und die Installation des "wpa_supplicant" Paketes. Danach sollte es, insofern die drahtlose Netzwerk- Karte unterstützt wird, prinzipiell möglich sein sich auch mit WPA/WPA2- Verschlüsselten Netzwerken zu verbinden.
Wenn man sich die Hilfe zum „ifconfig“- Befehl , in Bezug auf drahtlose Netzwerke, einmal näher ansieht, fallen drei interessante Befehls- Optionen/Parameter auf (siehe Bild).
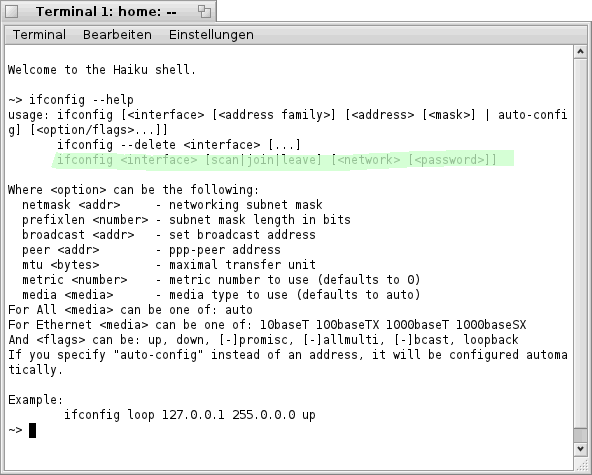
Die Option „join“ dient dazu, sich an einem drahtlosen Netzwerk anzumelden. Dies kann in folgender Form geschehen:
| ifconfig <Netzwerk- Adapter> join <SSID> <Passwort> |
Beispiel:
| ifconfig /dev/net/atheroswifi/0 join hades 12345 |
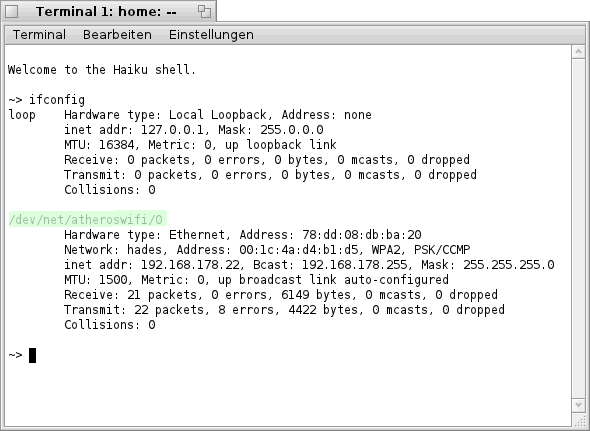
Den Namen des Netzwerk- Adapters kann man hierbei ebenfalls durch Eingabe des Befehls „ifconfig“ ohne weitere Parameter an der Kommandozeile in Erfahrung bringen (siehe Bild).
Woher weiß man nun aber mit welchem drahtlosen Netzwerk man sich verbindet und ob dieses überhaupt in Reichweite ist. Auch dafür kann der Befehl "ifconfig", mit dem geeigneten Parameter, benutzt werden. Der entsprechende Parameter ist in diesem Fall „scan“ und wird wie folgt verwendet:
| ifconfig <Netzwerk- Adapter> scan |
Beispiel:
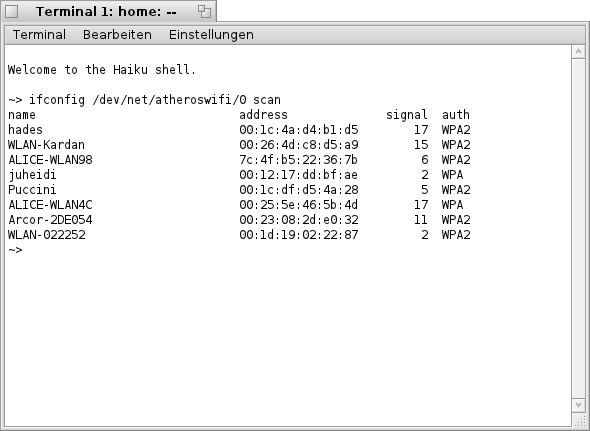
| ifconfig /dev/net/atheroswifi/0 scan |
Das Ergebnis könnte dann wie im nächsten Bild zu sehen, aussehen. Aufgelistet werden dabei die SSID’s (Namen) der einzelnen Netzwerke, sofern diese "sichtbar" sind, die Adresse (entspricht der MAC- Adresse des WLan- Routers), die Signalstärke und die Art der Verschlüsselung.
Zum Ende bleibt noch der Parameter „leave“. Mit diesem ist es möglich ein drahtloses Netzwerk wieder zu verlassen, sich also abzumelden. Der Aufruf ist dabei wie folgt:
| ifconfig <Netzwerk- Adapter> leave <SSID> |
Beispiel:
| ifconfig /dev/net/atheroswifi/0 leave hades |
Leider scheint der Befehl noch nicht wirklich integriert zu sein, oder er verhält sich auf meiner Test- Hardware anders als erwartet. Bei meinem Notebook erhalte ich die folgende Fehlermeldun
"ifconfig: Leaving network failed: Operation not supported"
Ein paar Tipps zum Schluss. Sollte die Verbindung mit einem drahtlosen Netzwerk, trotz aktueller Haiku- Version und installiertem "wpa_supplicant" – Paket, nicht zustande kommen, kann eventuell die Installation der aktuellen Wifi- Firmware(install-wifi-firmwares.sh) Abhilfe schaffen. Auch das manuelle Einschalten/Starten des Netzwerk- Adapters und seine Einstellung auf "automatisch" kann durchaus zum Erfolg führen. Ich selbst habe mir mit einem kleinen Script geholfen welches ihr im Anschluss finden könnt.
| #!/bin/sh ifconfig /dev/net/atheroswifi/0 up ifconfig /dev/net/atheroswifi/0 auto-config ifconfig /dev/net/atheroswifi/0 join hades abc123 |
Das Script schaltet zuerst die Netzwerk- Karte ein, denn bei meinen Tests habe ich bemerkt, dass die Netzwerk- Karte hin und wieder nach dem Hochfahren deaktiviert war. Als nächstes wird die Netzwerk- Karte in den "auto-config"- Modus (DHCP) versetzt und als letztes trete ich meinem WLan bei.
zurück zur Übersicht
yab - SSID's aller empfangbaren, drahtlosen Netzwerke ermitteln
Sonntag, 8. Januar 2012
In Anlehnung an meinen letzten Post möchte ich Euch heute zeigen wie man die verschiedenen Informationen auch per yab ermitteln kann. Beginnen möchte ich mit dem Ernitteln aller SSID's (Namen) der im Empfangsbereich vorhandenen drahtlosen Netzwerke.
Zuerst ermitteln wir per "ifconfig" die einzelnen Netzwerk- Interfaces und durchsuchen diese dann nach der Zeichenkette "wifi". Soweit ich in meinen Tests herausgefunden habe, haben alle drahtlosen Netzwerk- Adapter diese Zeichenkette in ihrem Namen. Anschließend werden, über den Befehl "ifconfig >Netzwerk- Interface> scan", alle drahlosen Netzwerke in der Umgebung aufgelistet. Das ganze in einem Array speichern und ein wenig filtern und schon bekommt man die gewünschten Informationen. Weitere Kommentare könnt Ihr wie immer dem Quelltext entnehmen.
Zurückgegeben wird ein String mit allen gefundenen SSID's welche, zur besseren Ansicht, durch jeweils ein "\n" getrennt sind.
Der Aufruf der Sub- Routine kann z.B. in folgender Form geschehen:
| print _GetAllSSIDs$() |
| export sub _GetAllSSIDs$() // lokale Variablen definieren local NumberOfTokens local SystemInfo$ local WifiAdapter$ local WifiNetworkNames$ dim Line$(1) // Liste aller Nertzwerk- Karten erstellen // den Befehl "ifconfig" ausführen und Ergebnis in // SystemInfo$ speichern SystemInfo$ = system$("ifconfig") // das Ergebnis ersteinmal in einzelne Zeile zerlegen NumberOfTokens = split(SystemInfo$, Line$(), "\n") // in den Zeilen mit führendem "/" nach dem String // "wifi" suchen (dies ist der Wifi- Adapter) for i = 1 to NumberOfTokens // die Zeile mit "dev" und "wifi" enthält den richtigen Adapter if (left$(Line$(i), 4) = "/dev") and (instr(Line$(i), "wifi")) then WifiAdapter$ = Line$(i) endif next // Nachdem der Wifi- Adapter ermittelt wurde, können nun // alle im Umkreis befindlichen, drahtlosen Netzwerke ermittelt // werden. // den Befehl "ifconfig scan" ausführen und das Ergebnis // in SystemInfo$ speichern SystemInfo$ = system$("ifconfig " + WifiAdapter$ + " scan") // das Ergebnis wieder in einzelne Zeilen auftrennen NumberOfTokens = split(SystemInfo$, Line$(), "\n") // die erste Zeile ignorieren, ist nur die Spaltenbeschriftung for i = 2 to NumberOfTokens // nur die ersten 33 Zeichen jeder Zeile lesen und die // Leerzeichen entfernen WifiNetworkNames$ = WifiNetworkNames$ + trim$(left$(Line$(i), 33)) + "\n" next i // das Ergebnis als durch "LF" getrennten String zurückgeben return WifiNetworkNames$ end sub |
yab - die aktuelle SSID ermitteln
Montag, 16. Januar 2012
Nachdem ich Euch bereits gezeigt habe wie man alle im Umkreis befindlichen bzw. alle empfangbaren SSID's ermitteln kann. Möchte ich Euch heute zeigen wie man die aktuelle SSID, sprich den Namen des Netzwerkes mit welchem man aktuell verbunden ist, herausbekommt. Auch hierfür greifen wir wieder auf den Befehl "ifconfig" zurück. Denn in den Daten zu jeder drahtlosen Netzwerk- Karte steht auch der Name des aktuellen drahtlosen Netzwerks. Zu finden ist dieser unmittelbar nach der Zeichenkette "Network:". Ist diese Zeichenkette nicht vorhanden, besteht entweder keine Verbindung zu einem drahtlosen Netzwerk oder es handelt sich um kein drahtloses Netzwerk.
Weiterführenden Kommentare und Informationen könnt Ihr wie immer dem Quelltext entnhemen.
Der Aufruf der Sub- Routine kann dabei z.B. wie folgt geschehen:
| print _GetCurrentSSID$() |
| export sub _GetCurrentSSID$() // lokale Variablendefinition local NumberOfTokens local SystemInfo$ local Info$ dim Line$(1) // den Befehl "ifconfig" ausführen und das Ergebnis in // SystemInfo$ speichern SystemInfo$ = system$("ifconfig") // das Ergebnis in einzelne Zeilen zerlegen ... NumberOfTokens = split(SystemInfo$, Line$(), "\n") for i = 1 to NumberOfTokens // ... und die richtige Zeile finden if (instr(Line$(i), "Network:")) then Info$ = Line$(i) break else Info$ = "Network: kein drahtloses Netzwerk verbunden" endif next // die Zeile in ihre einzelnen Informationen zerlegen NumberOfTokens = split(Info$, Line$(), ":,") // die gesuchte Information steht an 2. Stelle des Line$- Arrays return trim$(Line$(2)) end sub |
yab - FireWire- Schnittstelle erkennen
Freitag, 20. Januar 2012
Das neue Jahr hat begonnen und ich möchte Euch gleich zu Beginn ein klein wenig mehr Quelltext schenken. Da Haiku ja auch die FireWire- Schnittstelle unterstützt, möchte ich Euch heute zeigen wie man erkennen kann ob eine solche Schnittstelle im System vorhanden ist bzw. ob diese auch von Haiku erkannt wurde.
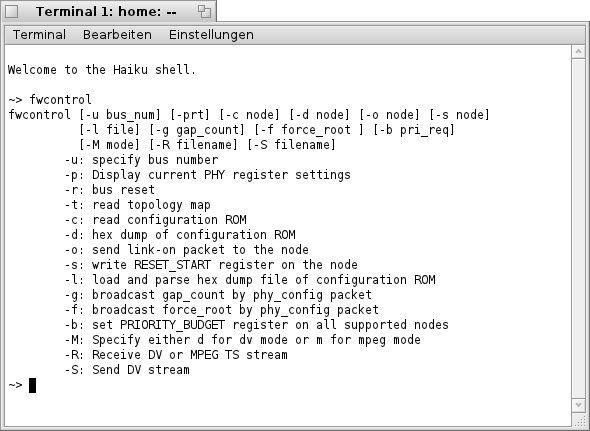
Um dies zu erledigen, benutzen wir den Kommandozeilen. Befehl "fwcontrol". Dieser gibt Auskunft darüber ob eine FireWire- Schnittstelle im System vorhanden ist bzw. unterstützt wird.
Gibt man nun im "Terminal" den Befehl "fwcontrol" ein, erhält man bei vorhandener FireWire- Schnittstelle folgende Ausgabe.
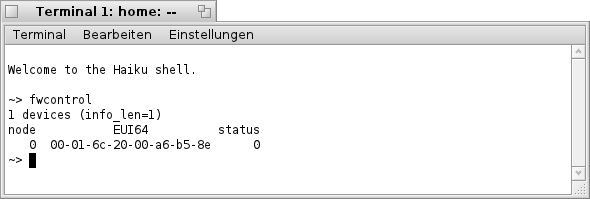
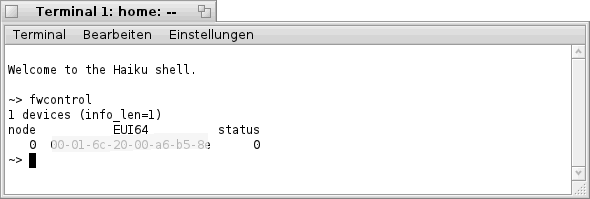
Es ist deutlich zu erkennen das hier eine FireWire- Schnittstelle gefunden wurde ("1 devices"). Ebenso wird der "extended unique identifier" (EUI64) im 64- bit- Format ausgegeben.
Ist keine FireWire- Schnittstelle im System vorhanden oder wird diese nicht unterstützt, sieht die Ausgabe wie folgt aus.
Mit Hilfe dieser Informationen kann das Vorhandensein der genannten Schnittstelle recht gut unterschieden bzw. nachgewiesen werden. Die verschiedenen Kommentare innerhalb des Quelltextes sollten die verschiedenen Schritte ausreichend dokumentieren.
| export sub _GetFireWire() // lokale Variablen Definition local SystemInfo$ local NumberOfTokens local FireWireCount dim Line$(1) // den Befehl "fwcontrol" aufrufen und Ergebnis in // SystemInfo$ speichern SystemInfo$ = system$("fwcontrol") // Prüfen ob SystemInfo$ Daten enthält ... if SystemInfo$ <> "" then // ... wenn ja, // das Ergebnis in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInfo$, Line$(), "\n") // in der ersten Zeile nach dem String "devices" // suchen if instr(Line$(1), "devices") then // wenn in der ersten Zeile der String "devices" // enthalten ist, SystemInfo$ nach Leerzeichen // neu zerlegen NumberOfTokens = split(SystemInfo$, Line$(), " ") // an der ersten Stelle steht nun die Anzahl der // im System vorhandenen FireWire- Schnittstellen FireWireCount = val(Line$(1)) else // wenn der String "devices" nicht in der ersten // Zeile vohanden ist, ist entweder keine FireWire- // Schnittstelle vorhanden oder sie wird nicht // unterstützt FireWireCount = 0 end if else // ... wenn nein, // dann keine FireWire- Schnittstelle(n) verfügbar FireWireCount = 0 end if // Ergebnis zurückgeben return FireWireCount end sub |
Der Aufruf der Sub- Routine kann dann z.B. in folgender Form geschehen.
| FW = _GetFireWire() print "Anzahl der FireWire- Schnittstellen im System: ", FW |
Als Ergebnis wird entweder "0", wenn keine FireWire- Schnittstelle vorhanden ist, oder die Anzahl der vorhandenen FireWire- Schnittstellen zurückgegeben.
zurück zur Übersicht
yab - "EUI64" der FireWire- Schnittstelle ermitteln
<br< Samstag, 28. Januar 2012
Da wir gerade bei der FireWire- Schnittstelle sind, möchte ich Euch gleich noch einen Weg zeigen, wie man, sofern eine FireWire- Schnitstelle vorhanden ist bzw. erkannt wurde, den "EUI64" ("extended unique identifier") ermitteln kann (siehe Bild).
Auch hierzu benutzen wir wieder den Kommandozeilen- Befehl "fwcontrol". Der folgende kleine Quelltext soll dies veranschaulichen. Zu beachten ist, das für die Funktion der Sub- Routine auch die Sub- Routine "_GetFireWire()", aus dem letzten Beitrag, benötigt wird. Die einzelnen Kommentare sollten die Vorgehensweise genügend dokumentieren.
| import GetFireWire export sub _GetFireWireEUI64$() // lokale Variablen Definition local NumberOfTokens1 local NumberOfTokens2 local SystemInfo$ local Result$ dim Line1$(1) dim Line2$(1) Result$ = "" // prüfen ob überhaupt eine FireWire- Schnittstelle im // System vorhanden ist if _GetFireWire() > 0 then // wenn ja, "fwcontrol" ausführen und das Ergebnis // in SystemInfo$ speichern SystemInfo$ = system$("fwcontrol") // alles in einzelne Zeilen zerlegen NumberOfTokens1 = split(SystemInfo$, Line1$(), "\n") // erst bei Zeile 3 beginnen dann alle weiteren Zeilen // lesen und durch "\n" getrennt an Result$ übergeben for i = 3 to NumberOfTokens1 - 1 NumberOfTokens2 = split(Line1$(i), Line2$(), " ") Result$ = Result$ + Line2$(6) + "\n" next i // Ergebnis zurückgeben return Result$ else // wenn kein EUI64 gefunden wurde return "No 'extended unique identifier' found." end if end sub |
Der Aufruf der Sub- Routine kann dann z.B. in folgender Form geschehen.
| EUI64$ = _GetFireWireEUI64() print EUI64$ |
Als Ergebnis wird entweder "No 'extended unique identifier' found.", wenn keine FireWire- Schnittstelle vorhanden ist, oder die entsprechenden EUI64- Strings durch "\n" getrennt zurückgegeben. Prinzipiell sollte die Routine auch funktionieren wenn mehr als eine FireWire- Schnittstelle gefunden wird. Auf Grund mangelndem Equipments konnte ich dies aber leider nicht verifizieren.
zurück zur Übersicht
Scripting - Text- Ausgaben unter Kontrolle
Mittwoch, 1. Februar 2012
Als ich dieser Tage, bei meinen Exkursionen durch die Haiku- Befehlszeile, mal wieder in den Tiefen des Betriebssystems unterwegs war, ist mir ein kleiner, aber dennoch feiner, Befehl aufgefallen. Mit diesem Befehl lassen sich, TExt- Dateien oder - Ausgaben, auf sehr einfache Weise formatieren. Es handelt sich hierbei um den Befehl "awk", der die genannten Aufgaben mit Bravour erfüllt. Ein paar Beispiele sollen dies veranschaulichen.
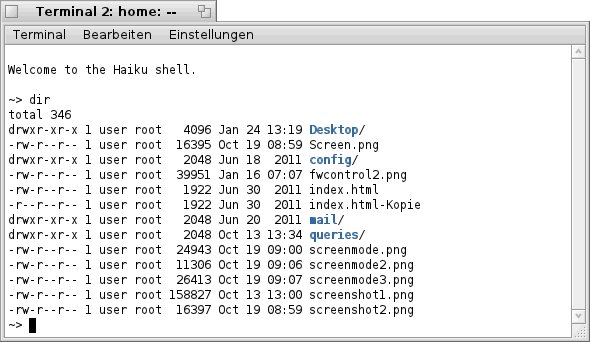
Der Aufruf von "dir" fördert z.B. folgende Ausgabe zu Tage (siehe Screenshot). Die Ausgabe hat, wie deutlich zu sehen ist, 9 Spalten. Auf diese läßt sich mit Hilfe des Befehls "awk" einzeln zugreifen.
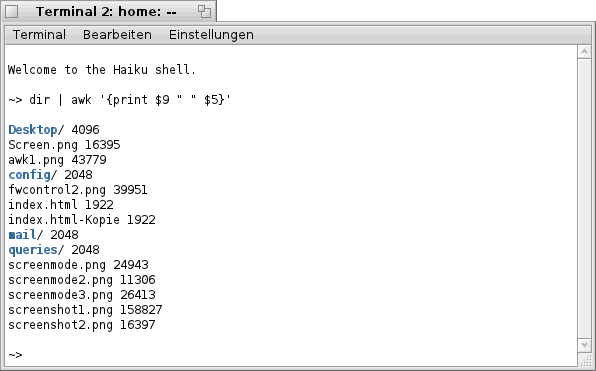
So zeigt der untenstehende Befehls- Aufruf das im Bild angezeigte Ergebnis. Mit dem Platzhalter "$" gefolgt von der Nummer der Spalte, läßt sich auf diese zugreifen. Angezeigt werden in diesem Beispiel nur der Dateiname und die Größe der Datei.
| dir | awk '{print $9 " " $5}' |
Wenn man den Befehl noch etwas weiter ausbaut, kann man z.B. auch die Größen der einzelnen Dateien addieren und als Ergebnis ausgeben (siehe Screenshot unten).
| dir *.png | awk '{ sum += $5 }; { print $5 " " $9 }; END { print sum " bytes gesamt" }' |
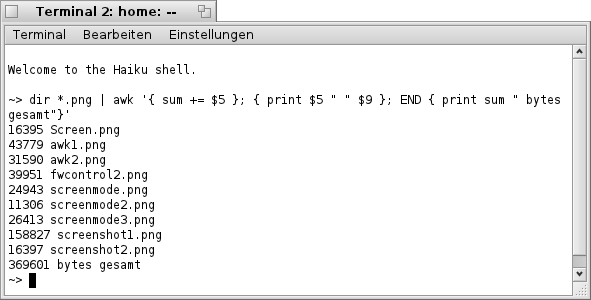
Wie in den angeführten Beispielen ersichtlich ist, kann mit dem Befehl "awk" gezielt auf Spalten eines Textes zugegriffen werden. Als Trennzeichen der einzelnen Spalten dient das Leerzeichen. Es ließen sich sicherlich noch weitere Beispiele aufzeigen, was jedoch den Rahmen an dieser Stelle durchaus sprengen würde. Deshalb möchte ich es hier enden lassen und hoffe ihr habt viel Spaß beim Probieren und Tüfteln.
zurück zur Übersicht
yab - Größer einer Datei ermitteln
Donnerstag, 9. Februar 2012
Nachdem ich Euch vor einiger Zeit gezeigt habe wie man das Datum und die Uhrzeit einer Datei ermitteln kann, möchte ich Euch heute zeigen wie man auch die Größe einer Datei herausfindet. Wege zu diesem Ziel gibt es sicherlich recht viele und so habe ich mir einmal zwei herausgesucht. Der erste, klassische, Weg wird wahrscheinlich häufiger beschritten. Der zweite Weg den ich Euch zeigen möchte basiert hingegen auf einem Beitrag aus der jüngeren Vergangenheit, nämlich "Haiku - Text- Ausgaben unter Kontrolle.
Die Quelltexte sind wieder mit reichlich Kommentaren gespickt und so sollte das Verständnis für die Zusammenhänge auch nicht zu kurz kommen.
Beispiel 1 - der klassische Weg
| export sub _GetFileSize(Filename$) // Variablen definieren local SystemInput$ local NumberOfTokens local Result dim Position$(1) // prüfen ob die angegebene Datei existiert if (not system("test -e " + Filename$)) then // den Befehl "LS -l" ausführen und Ausgabe in SystemInput$ speichern SystemInput$ = system$("ls -l " + Filename$) // SystemInput$ in die einzelnen Bestandteile zerlegen NumberOfTokens = split(SystemInput$, Position$(), " .") // an Position 5 (Dateigröße) steht die gewünschte Information Result = val(Position$(5)) else // wenn Datei nicht gefunden, Ergebnis = 0 Result = 0 endif // Ergebnis zurückliefern return Result end sub |
Beispiel 2 - ein etwas anderer Weg
| export sub _GetFileSize(Filename$) // Variablen definieren local SystemInput$ local Result dim Position$(1) // prüfen ob die angegebene Datei existiert if (not system("test -e " + Filename$)) then // den Befehl "LS -l [Dateiname] | awk '{print $5}'" ausführen // und Ausgabe in SystemInput$ speichern SystemInput$ = system$("ls -l " + Filename$ + " | awk '{print $5}'") // in diesem Fall enthält SystemInput$ bereits den richtigen Wert Result = val(trim$(SystemInput$)) else // wenn Datei nicht gefunden, Ergebnis = 0 Result = 0 endif // Ergebnis zurückliefern return Result end sub |
Beide Sub- Routinen liefern das gleiche Ergebnis und können z.B. mit dem folgenden Befehl aufgerufen werden.
| print _GetFileSize("[Pfad zur entsprechenden Datei]")' |
yab - Größe eines Verzeichnisses ermitteln
Montag, 13. Februar 2012
Analog zum Ermitteln der Größe einer Datei, aus meinem letzten yab- Beitrag, möchte ich Euch heute zeigen wie man mit ein paar kleinen Änderungen am Quelltext auch die Größe eines Verzeichnisses herausfinden kann. Dieses Beispiel lehnt sich an "Beispiel 2" an und nutzt ebenfalls den Befehl "awk", wie bereits unter "Haiku - Text- Ausgaben unter Kontrolle" beschrieben. Damit und mit den entsprechenden Parametern für den "ls"- Befehl ist das Ganze relativ einfach umgesetzt.
| export sub _GetDirSize(Path$) // Variablen definieren local SystemInput$ local Result local AWK$ dim Position$(1) AWK$ = " | awk '{sum+=$5}; END {print sum}'" // prüfen ob das angegebene Verzeichnis existiert if (not system("test -d " + Path$)) then // den Befehl "LS -l -R -A | awk '{sum+=$5}; END {print sum}' ausführen // und Ausgabe in SystemInput$ speichern SystemInput$ = system$("ls -l -R -A " + Path$ + AWK$) // in diesem Fall enthält SystemInput$ bereits den richtigen Wert Result = val(trim$(SystemInput$)) else // wenn Datei nicht gefunden, Ergebnis = 0 Result = 0 endif // Ergebnis zurückliefern return Result end sub |
Als erstes "bauen" wir den AWK$ zusammen, denn der Befehl "awk" nimmt uns an dieser Stelle prinzipiell die gesamte Arbeit ab. Er sorgt für das zusammenzählen der einzelnen Datei- Größen "{sum+=$5}" (wir erinnern uns, $5 steht für die 5. Position, also die Datei- Größe, der Ausgabe bei "dir" bzw. "ls -l") und die Ausgabe der errechneten Summe "{print sum}".
Als nächstes prüfen wir "test -d" ob es sich bei dem übergebenen Pfad auch wirklich um ein Verzeichnis handelt und wenn ja, lassen wir den Befehlen ihren freien Lauf. Sollte der Pfad nicht vorhanden oder kein Verzeichnis sein, wird "0" zurückgegeben.
zurück zur Übersicht
yab - installierte "OptionalPackages" ermitteln
Dienstag, 21. Februar 2012
Heute möchte ich Euch, an Hand zweier Beispiele, zeigen wie man die installierten "OptionalPackages", welche mit Hilfe des Befehls "installoptionalpackage" installiert werden können, per "yab" ermitteln kann. Bei meinen Experimenten zu diesem Thema ist mir aufgefallen, das der Schalter "-s", welcher eine Liste der installierten Pakete anzeigen soll, leider einen Fehler Produziert. Doch auch dafür habe ich einen Workaround gefunden.
In ersten Beispiel verwende ich zum Auflisten der installierten Pakete den Befehl "installoptionalpackage -l" und suche mir dann in der Ausgabe die Zeile mit dem Inhalt "Optional Packages that have been installed:". Die nachvollgende Zeile enthält dann die gewünschten Informationen. Diese werden gelesen und die Suche wird abgebrochen. Anschließend werden noch die Leerzeichen durch "\n" ersetzt, sodaß wir einen durch "LineFeed" getrennten String erhalten, fertig. Zu beachten ist an dieser Stelle das, eine Internet- Verbindung bestehen muß, da der Befehl "installoptionalpackage -l" auch die die Pakete ermittelt, welche noch installiert werden können.
Der Aufruf der Sub- Routine kann dabei folgendermaßen geschehen:
| InstalledPackages$ = _GetInstalledOptionalPackages$() print InstalledPackages$ |
| export sub _GetInstalledOptionalPackages$() // Variablen definieren local SystemInput$ local NumberOfTokens local OP$ local Result$ dim Line$(1) // den Befehl "installoptionalpackage -l" aufrufen // und Ausgabe in SystemInput$ speichern SystemInput$ = system$("installoptionalpackage -l") // alles in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInput$, Line$(), "\n") // die einzelnen Zeilen durchgehen und auswerten for i = 1 to NumberOfTokens // wenn diese Zeile gefunden wird, stehen in der nächsten Zeile // die gewünschten Daten if (Line$(i) = "Optional Packages that have been installed:") then // Daten übernehmen und Suchvorgang beenden OP$ = Line$(i + 1) break endif next i // den erhaltenen String wieder zerlegen und die // Leerzeichen gegen "\n" (LineFeed) austauschen NumberOfTokens = split(OP$, Line$(), " ") for i = 1 to NumberOfTokens Result$ = Result$ + Line$(i) + "\n" next i // Ergebnis zurückliefern return Result$ end sub |
Eine andere Möglichkeit die gewünschten Informationen zu erhalten ist Folgende. Alle installierten, optionalen Pakete werden zeilenweise in der Datei "/boot/common/data/optional-packages/InstalledPackages" festgehalten. Damit ist es aus sehr einfache Weise möglich diese zu erfragen. Auch ist es für diesen Weg nicht erforderlich eine bestehende Internet- Verbindung zu haben. Das untenstehende Beispiel soll dies verdeutlichen.
Zunächst öffnen wir die genannte Datei zum Lesen und holen alle Informationen bis das Ende der Datei erreicht ist und schreiben diese, getrennt durch "\n" in einen String. Das war es dann auch schon. Anschließend können wir uns das Ergebnis wie folgt ansehen.
| InstalledPackages$ = _GetInstalledOptionalPackages$() print InstalledPackages$ |
| export sub _GetInstalledOptionalPackages$() // Variablen definieren local Result$ local Line$ // in der Datei "/boot/common/data/optional-packages/InstalledPackages" // finden sich die Einträge aller installierten Pakete, diese einfach // Zeilenweise auslesen open "/boot/common/data/optional-packages/InstalledPackages" for reading as #1 // bis das Ende der Datei erreicht ist ... while(not eof(1)) // jede Zeile lesen ... line input #1 Line$ // in Result$ speichern und ein "\n" anfügen Result$ = Result$ + Line$ + "\n" wend // Datei wieder schließen ... close #1 // und Ergebnis zurückgeben return Result$ end sub |
yab - installierbare "OptionalPackages" ermitteln
Samstag, 25. Februar 2012
Nachdem ich Euch in meinem letzten Beitrag verschiedene Möglichkeiten gezeigt habe wie man mit "yab" die bereits installierten optionalen Pakete ermitteln kann, möchte ich Euch heute einen Weg zeigen, wie man auch die noch zu installierenden (sprich die noch nicht installierten) optionalen Pakete abfragen kann. Als Grundlage dient die Sub- Routine aus dem ersten Beispiel. Mit zwei kleinen Änderungen kann diese direkt für die neue Aufgabe übernommen werden. Auch hier ist darauf zu achten, das dies nur funktioniert wenn eine Internet- Verbindung besteht.
Als erstes geben wir der Sub- Routine einen neuen anderen Namen und als zweites tauschen wir die Zeile
| if (Line$(i) = "Installable Optional Packages:") then |
Der resultierende Quelltext sollten dann wie folgt aussehen. Der Rest bleibt gleich und die Sub- Routine kann dann wie folgt aufgerufen werden.
| InstallablePackages$ = _GetInstallableOptionalPackages$() print InstallablePackages$ |
| export sub _GetInstallableOptionalPackages$() // Variablen definieren local SystemInput$ local NumberOfTokens local OP$ local Result$ dim Line$(1) // den Befehl "installoptionalpackage -l" aufrufen // und Ausgabe in SystemInput$ speichern SystemInput$ = system$("installoptionalpackage -l") // alles in einzelne Zeilen zerlegen NumberOfTokens = split(SystemInput$, Line$(), "\n") // die einzelnen Zeilen durchgehen und auswerten for i = 1 to NumberOfTokens // wenn diese Zeile gefunden wird, stehen in der nächsten Zeile // die gewünschten Daten if (Line$(i) = "Installable Optional Packages:") then // Daten übernehmen und Suchvorgang beenden OP$ = Line$(i + 1) break endif next i // den erhaltenen String wieder zerlegen und die // Leerzeichen gegen "\n" (LineFeed) austauschen NumberOfTokens = split(OP$, Line$(), " ") for i = 1 to NumberOfTokens Result$ = Result$ + Line$(i) + "\n" next i // Ergebnis zurückliefern return Result$ end sub |
Scripting - Haiku und der "test"- Befehl
Samstag, 3. März 2012
Bei meinen Ausflügen durch die Wildnis der Kommando- Zeile bin ich einmal mehr über einen recht interessanten Befehl gestolpert. Dieser Befehl ist mir auch schon in einigen "yab"- Programmen über den Weg gelaufen und ich selbst habe ihn auch schon benutzt. Es handelt sich hierbei um den Befehl "test".
Leider bietet der Befehl selbst keinerlei Hilfe die, schlummernd, irgendwo im System darauf warten würde aufgerufen zu werden. Aus dieser Not heraus habe ich mich bei verschiedenen, anderen Unix- Derivaten auf die Suche gemacht und bin dabei auch fündig geworden.
Bei meinen ersten Versuchen, heraus zu finden welche der reichlich vorhandenen Optionen von Haiku unterstützt werden bin ich vorerst auf folgende gestoßen.
| test -d [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und ist ein Verzeichnis
| test -e [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert
| test -f [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und ist eine reguläre Datei
| test -h [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und ist ein symbolischer Link
| test -r [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und ist lesbar
| test -s [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und hat eine Größe größer als 0
| test -w [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und ist beschreibbar
- (aus einem mir noch unbekannten Grund liefert diese Option immer 1)
| test -x [Datei/Verzeichnis] |
- True = Datei/Verzeichnis existiert und ist ausführbar
Der "test"- Befehl liefert als Ergebnis entweder 0 (False) oder 1 (True) zurück.
zurück zur Übersicht
yab - ... und wir "test"- en weiter
Mittwoch, 7. März 2012
Nach der ganzen Erklärerei zum "test"- Befehl folgt nun, Trommelwirbel, natürlich auch die Umsetzung in "yab". Die Sub- Routinen sind dabei sehr einfach gehalten und bedürfen auch keiner großen Erklärung.
Die Sub- Routine "_IsDir()" prüft ob es sich bei der/dem angegebenen Datei/Verzeichnis um ein Verzeichnis handelt und gibt entsprechend 0 (False) oder 1 (True) zurück.
Der Aufruf der Sub- Routine kann z.B. wie folgt geschehen.
| print _IsDir("/boot/home/") |
| export sub _IsDir(Filename$) // den Befehl "TEST -d" ausführen // (-d = Datei existiert und ist ein Verzeichnis) if (system("test -d " + Filename$)) then return false else return true endif end sub |
Die Sub- Routine "_IsExecutable()" prüft ob die/das angegebene Datei/Verzeichnis ausführbar ist und gibt entsprechend 0 (False) oder 1 (True) zurück.
Der Aufruf der Sub- Routine kann z.B. wie folgt geschehen.
| print _IsExecutable("/boot/home/index.html") |
| export sub _IsExecutable(Filename$) // den Befehl "TEST -x" ausführen // (-x = Datei existiert und ist ausführbar) if (system("test -x " + Filename$)) then return false else return true endif end sub |
Die Sub- Routine "_IsFile()" prüft ob es sich bei der/dem angegebenen Datei/Verzeichnis um eine Datei handelt und gibt entsprechend 0 (False) oder 1 (True) zurück.
Der Aufruf der Sub- Routine kann z.B. wie folgt geschehen.
| print _IsFile("/boot/home/index.html") |
| export sub _IsFile(Filename$) // den Befehl "TEST -f" ausführen // (-f = Datei existiert und ist eine reguläre Datei) if (system("test -f " + Filename$)) then return false else return true endif end sub |
yab - wir "test"- en weiter (Teil 2)
Donnerstag, 15. März 2012
So, wegen der Vollständigkeit hier nun auch noch die restlichen yab- Umsetzungen zum "test"- Befehl. Die Sub- Routinen sind, wie auch schon die letzten, sehr einfach gehalten und müssen nicht näher erklärt werden.
Die Sub- Routine "_IsGreaterThanZero()" prüft ob die/das angegebene Datei/Verzeichnis existiert und eine Größe, größer als 0 hat. Existiert die/das Datei/Verzeichnis und hat eine Größe, größer als 0, wird als Ergebnis 1 (True), andernfalls 0 (False) zurückgegeben.
Der Aufruf der Sub- Routine kann z.B. wie folgt geschehen.
| print _IsGreaterThanZero("/boot/home/index.html") |
| export sub _IsGreaterThanZero(Filename$) // den Befehl "TEST -f" ausführen // (-s = Datei existiert und und ist größer als 0 bytes) if (system("test -s " + Filename$)) then return false else return true endif end sub |
Die Sub- Routine "_IsLink()" prüft ob die/das angegebene Datei/Verzeichnis ein symbolischer Link ist und gibt entsprechend 0 (False) oder 1 (True) zurück.
Der Aufruf der Sub- Routine kann z.B. wie folgt geschehen.
| print _IsLink("/boot/home/index.html") |
| export sub _IsLink(Filename$) // den Befehl "TEST -h" ausführen // (-h = Datei existiert und ist ein symbolische Verknüpfung/Link) if (system("test -h " + Filename$)) then return false else return true endif end sub |
Die Sub- Routine "_IsReadable()" prüft ob die/das angegebenen Datei/Verzeichnis existiert und lesbar ist und gibt entsprechend 0 (False) oder 1 (True) zurück.
Der Aufruf der Sub- Routine kann z.B. wie folgt geschehen.
| print _IsFile("/boot/home/index.html") |
| export sub _IsReadable(Filename$) // den Befehl "TEST -r" ausführen // (-r = Datei existiert und ist lesbar) if (system("test -r " + Filename$)) then return false else return true endif end sub |
Auf das Beispiel mit der Funktion "_IsWritable()" habe ich an dieser Stelle bewußt verzichtet, da das Ergebnis dieser Funktion, aus einem unerfindlichen Grund immer 1 ist. Möglicherweise handelt es sich dabei auch um einen Bug.
zurück zur Übersicht
Scripting - ... und der "test"- Befehl (Teil 2)
Freitag, 23. März 2012
Nachdem ich Euch in einem der letzten Beiträge den Befehl "test" etwas näher gebracht und gezeigt habe wie man Dateien auf ihren Typ und ihre Existenz prüfen kann, möchte ich Euch heute noch ein paar weitere interessante Möglichkeiten mit auf den Weg geben.
Mit dem "test"- Befehl ist es nicht nur möglich irgendwelche Dateien oder Ordner auf "weiß der Teufel" was zu prüfen, man kann in einem recht moderaten Umfang auch arithmetische und String- Operationen durchführen. Bei Erfolg wird 1 (True) und bei Misserfolg wird 0 (False) zurückgegeben.
| test [String1] = [String2] |
- True = [String1] ist gleich [String2]
| test [String1] != [String2] |
- True = [String1] ist nicht gleich [String2]
Beispiel:
| #! /bin/sh if test "AAA" = "BBB"; then echo "String1 (AAA) ist gleich String2 (BBB)" else echo "String1 (AAA) ist nicht gleich String2 (BBB)" fi |
| test [Integer1] -eq [Integer2] |
- True = [Integer1] ist gleich [Integer2]
| test [Integer1] -ge [Integer2] |
- True = [Integer1] ist größer als oder gleich [Integer2]
| test [Integer1] -gt [Integer2] |
- True = [Integer1] ist größer als [Integer2]
| test [Integer1] -le [Integer2] |
- True = [Integer1] ist kleiner als oder gleich [Integer2]
| test [Integer1] -lt [Integer2] |
- True = [Integer1] ist kleiner als [Integer2]
| test [Integer1] -ne [Integer2] |
- True = [Integer1] ist nicht gleich [Integer2]
Beispiel:
| #! /bin/sh if test 128 -eq 128; then echo "die beiden Zahlen sind gleich" else echo "die beiden Zahlen sind nicht gleich" fi |
Die Beispiel- Dateien habe ich mit "StyleEdit" erstellt. Es ist darauf zu achten das die erstellten Shell- Scripte noch die "Ausführen"- Berechtigung bekommen müssen. Dies kann z. B. mit dem folgenden Befehl bewerkstelligt werden.
| chmod +x [Dateiname] |
Scripting - ... und der "test"- Befehl (Teil 3)
Dienstag, 27. März 2012
Um der Vollständigkeit Rechnung zu tragen, gibts heute den dritten und damit auch letzten Teil zum Thema "test"- Befehl. Einige Dinge, außer den bereits gezeigten, lassen sich nämlich noch mit dem "test"- Befehl bewerkstelligen.
So kann mit den folgenden Optionen z.B. geprüft werden, ob ein beliebiger String eine Länge größer als 0 besitzt.
| test -n [String] |
- True = [String] ist länger als 0 Zeichen
| test -z [String] |
- True = [String] ist 0 Zeichen lang
Beispiel:
| #! /bin/sh if test -n "AAA"; then echo "String1 (AAA) hat eine Länge > 0." else echo "String1 (AAA) ist 0 Zeichen lang." fi |
Die folgenden beiden Optionen dienen dazu, zwei Dateien miteinander zu vergleichen und herauszufinden welche der Dateien neuer bzw. älter ist.
| test [Datei1] -nt [Datei2] |
- True = [Datei1] ist neuer als [Datei2]
| test [Datei1] -ot [Datei2] |
- True = [Datei1] ist älter als [Datei2]
Beispiel:
| #! /bin/sh touch test1.txt sleep 5 touch test2.txt if test "test1.txt" -nt "test2.txt"; then echo test1.txt ist älter als text2.txt else echo test1.txt ist neuer als text2.txt fi |
Die Beispiel- Dateien habe ich wieder mit "StyleEdit" erstellt. Es ist ebenfalls wieder darauf zu achten das die erstellten Shell- Scripte noch die "Ausführen"- Berechtigung bekommen müssen. Dies kann z. B. mit dem folgenden Befehl bewerkstelligt werden.
| chmod +x [Dateiname] |
Scripting - "touch"- me
Mittwoch, 4. April 2012
So, heute gibt's mal wieder einen kleinen Ausflug in Richtung "Kommandozeilen- Dschungel", und ich werde Euch zeigen wie man mit einfachen Mitteln eine Datei anlegen und deren Datum verändern kann. Alle was wir dafür benötigen hat Haiku bereits an Board und es sind keine weiteren Programme notwendig.
Wie viele sicherlich schon wissen, ist es möglich mit Hilfe des Kommandozeilen- Befehls "touch", auf einfache Art und Weise eine Datei anzulegen. Folgendes, kleines Beispiel demonstriert dies einmal. Wir öffnen ein Terminal und geben an der Kommandozeile folgendes ein:
| touch datei.txt |
Wenn Ihr nun Euer Datei- System einmal näher betrachtet ("dir"), werdet Ihr feststellen, das sich eine neue Datei, mit dem Namen "datei.txt" im aktuellen Ordner befindet. Die Größe der Datei ist 0 Byte, klar wir haben ja auch noch nichts in die Datei hineingeschrieben.
Will man nun das Änderungs- Datum oder das Datum des letzten Zugriffs auf die Datei ändern, kann man wie folgt vorgehen:
| touch -m -t 200001010000.00 datei.txt |
Mit dem Parameter "-m" teilen wir dem Programm mit, das wir das Änderungs- Datum der Datei modifizieren wollen. Der Parameter "-t" teilt dem Programm mit, das wir einen Time- Stamp für das Datum angeben wollen. Die folgende, kryptische Zeichenkette ist der Time- Stamp, und zuletzt sagen wir dem Programm noch, welche Datei wir verändern wollen.
Der Time- Stamp setzt sich dabei wie folgt zusammen:
200001010000.00 = 2000-01-01-00-00-00 = YYYY-MM-DD-hh-mm-ss
Unsere Datei wurde demnach am 01.01.2000 um 00:00:00 Uhr das letzte Mal geändert, kann das stimmen...???
Um nun das Datum des letzten Zugriffs auf die Datei zu ändern, tauschen wir einfach den Parameter "-m" durch den Parameter "-a" aus.
| touch -a -t 200001010000.00 datei.txt |
Leider habe ich bisher noch keine Möglichkeit gefunden auch das Erstell- Datum zu ändern. Dies scheint so nicht vorgesehen zu sein. Auch mit dem Datum des letzten Zugriffs ist das so eine Sache, man kann es zwar ändern, aber sehen kann man es nirgends. Naja, ich bleibe auf jeden Fall am Ball und werde Euch berichten wenn ich hier weiteres ausgegraben habe.
zurück zur Übersicht
Haiku - Umbenennen mal anders
Sonntag, 8. April 2012
Heute nur ein kleiner Tipp am Rande, über den ich mehr oder weniger durch Zufall gestolpert bin. Um unter Haiku Dateinamen zu ändern gibt es der Möglichkeiten gar viele. Um dem Ganzen eine weitere hinzuzufügen habe ich mir diesen Beitrag einfallen lassen.
Wenn Ihr auf einer beliebigen Datei, z.B. auf dem Desktop, die rechte Mouse- Taste drückt, erscheint das folgende, kleine Popup- Menü aus welchen Ihr die Option "Datei-Info" wählt.
Klickt man, im nun erscheinenden Fenster, mit der linken Mouse- Taste direkt auf den Dateinamen, kann dieser an Ort uns Stelle editiert werden.
Das Ganze sieht dann wie folgt aus.
So, und nun viel Spaß beim Dateien umbenennen, auch wenn der beschriebene Weg nicht sonderlich effektiv ist, so funktioniert er zumindest.
zurück zur Übersicht
Scripting - "notify" me
Montag, 16. April 2012
So, weiter geht's mit der Reise durch die wilde Welt der Kommandozeile. Heute möchte ich Euch zeigen wie Ihr eigene Nachrichten, mit Hilfe des "notify"- Befehls anzeigen könnt. Alles was wir dafür benötigen ist in Haiku bereits an Board.
Ruft man den Befehl "notify" mit dem Parameter "--help" auf zeigt dieser uns eine Liste mit den verschiedenen Möglichkeiten welche sich uns nun bieten.
So bekommen wir bereits mit einem einfachen
| notify --app "MyApp" --title "MyTitle" "Hello World" |
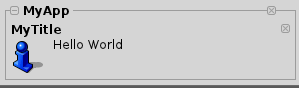
unser erstes Informations- Fenster angezeigt.
Die beiden Parameter "--app" und "--title" müssen immer angegeben werden, da der Befehl "notify" andern Falls einen Fehler ausgibt.
Erweitern wir nun unseren ersten Versuch um den Parameter "--timeout", können wir auch festlegen wie lange unsere Nachricht angezeigt werden soll. Die Angabe der Zeit erfolgt hierbei in Sekunden. Unser Beispiel sollte nun wie folgt aussehen.
| notify --app "MyApp" --title "MyTitle" --timeout 5 "Hello World" |
Das Nachrichten- Fenster kann aber auch verschiedene Formen, für verschiedene Ereignisse annehmen. Dies wird über den Parameter "--type" gesteuert. Die Optionen dafür sind "information", "important", "error" und "progress". Erweitern wir nun unsere Befehls- Zeile wie folgt.
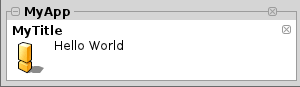
Ein Sonderfall unter den "Typen" stellt dabei "progress" dar. Um ein Nachrichten- Fenster mit einer Fortschritts- Anzeige auszustatten sind zwei weitere Parameter notwendig. Zum einen wäre das "--progress" und zum Anderen "--messageID".
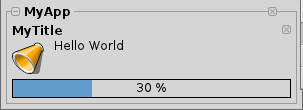
Mit "--progress" und einem Wert zwischen 0.0 und 1.0 kann man die Fortschritts- Anzeige beeinflussen. "--messageID" wird benötigt, um auch das richtige Nachrichten- Fenster auszuwählen. Das folgende Beispiel zeigt dies mit Hilfe eines kleinen Scripts.
| #!/bin/sh notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.1 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.2 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.3 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.4 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.5 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.6 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.7 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.8 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 0.9 --messageID 1 "Hello World" sleep 1 notify --app "MyApp" --title "MyTitle" --timeout 10 --type progress --progress 1.0 --messageID 1 "Hello World" sleep 1 |
Herauskommen sollte dabei ein Notification- Fenster das wie folgt aussieht. Dabei füllt sich die Fortschritts- Anzeige in 10 Schritten.
yab - Hash- Werte ermitteln
Mittwoch, 25. April 2012
So, in meinem heutigen Beitrag möchte ich Euch zeigen wie man Hash- Werte von beliebigen Dateien, mit "yab" ermitteln kann. Leider bietet uns "yab" keine direkte Unterstützung für diese Funktionen an, aber wofür gibt es denn den "system$"- Befehl.
Das erste Beispiel zeigt wie man den "MD5- Hash" einer Datei ermitteln kann, daß zweite Beispiel zeigt wie man den "SHA1- Hash" einer Datei ermittelt. Beide Sub- Routinen sind recht kurz gehalten und bedürfen keiner großen Erläuterung. Die wichtigsten Dinge sind bereits im Quellcode vermerkt.
Noch ein kleiner Tipp am Rande. Da "yab" auch nicht die Möglichkeit bietet entsprechende Hash- Werte von beliebigen Strings zu erstellen, könnte man die Sub- Routinen dahingehend abändern. Denn erstellt man selbst eine Datei, schreibt in diese den gewünschten String und ermittelt dann den benötigten Hash- Wert, erhält man das gleiche Ergebnis das eine entsprechende String- Funktion liefern würde.
Der Aufruf der beiden Beispiel- Sub- Routinen kann z.B. in Folgender Form erfolgen. Anschließend wird der entsprechende Hash- Wert zurückgegeben. Sollte die angegebene Datei nicht gefunden werden, wird "file not found" zurückgegeben.
| print _GetSHA1$("/boot/home/Desktop/textfile") |
oder entsprechend
| print _GetMD5$("/boot/home/Desktop/textfile") |
| export sub _GetSHA1$(Filename$) // Variablen definieren local SystemInput$ local NumberOfTokens local Result$ dim Position$(1) // prüfen ob die angegebene Datei existiert if (not system("test -e " + Filename$)) then // den Befehl "SHA1SUM" ausführen und Ausgabe in SystemInput$ speichern SystemInput$ = system$("sha1sum " + Filename$) // SystemInput$ in die einzelnen Bestandteile zerlegen NumberOfTokens = split(SystemInput$, Position$(), " ") // an Position 1 steht die gewünschte Information Result$ = Position$(1) else Result$ = "file not found" endif return Result$ end sub |
| export sub _GetMD5$(Filename$) // Variablen definieren local SystemInput$ local NumberOfTokens local Result$ dim Position$(1) // prüfen ob die angegebene Datei existiert if (not system("test -e " + Filename$)) then // den Befehl "MD5SUM" ausführen und Ausgabe in SystemInput$ speichern SystemInput$ = system$("md5sum " + Filename$) // SystemInput$ in die einzelnen Bestandteile zerlegen NumberOfTokens = split(SystemInput$, Position$(), " ") // an Position 1 steht die gewünschte Information Result$ = Position$(1) else Result$ = "file not found" endif return Result$ end sub |
yab - den Inhalt der Partitions- Tabelle ermitteln
Montag, 7. Mai 2012
Obwohl "yab" ja leider keine Anbindung an die verschiedenen Haiku- API's besitzt und auch nicht direkt auf Hardware zugreifen kann, bedeutet das noch lange nicht, das es nicht doch einen Weg gibt.
Dank des, sehr mächtigen, "system$"- Befehls und ein wenig Kommandozeilen- Gewurschtel ist es durchaus möglich z.B. die Partitions- Tabelle auszulesen.
Für diesen Zweck nutzen wir einmal mehr den Befehl "dd" mit dessen Hilfe wir ein fach den ersten Sektor der Festplatte in eine Datei schreiben. Dies kann folgendermaßen geschehen.
| dd if=/dev/disk/ata/0/master/raw of=sector.tmp count=1 |
|
Wichtig an dieser Stelle ist, das das entsprechende "raw"- Device verwendet wird, da wir bei "0", "1", etc. den ersten Sektor der jeweiligen Partition, nicht aber der eigentliche Festplatte lesen würden. |
So, nachdem nun also den ersten Sektor der Festplatte in die Datei "sector.tmp" geschrieben haben, können wir nun damit beginnen die entsprechenden Informationen zu extrahieren. Interessant sind für uns in diesem Zusammenhang nur die 64 Byte, welche ab Position 446 zu finden sind. Den genauen Aufbau der Partitionstabelle möchte ich mir an dieser Stelle jedoch sparen, da dies den Rahmen etwas sprengen würde. Nachlesen kann man das Ganze aber unter folgendem Link.
| "80|00|00|00|eb|....." |
Der Aufruf der Sub- Routine kann z.B. folgendermaßer erfolgen.
| print _GetPartitionTable$("/dev/disk/ata/0/master/raw") |
Was genau man mit diesen Informationen wie anstellen kann, werde ich Euch in den nächsten Folgen einer "yab- Tutorial- Reihe" zeigen.
| // es muß immer der "raw"- Eintrag des entsprechenden // Laufwerks übergeben werden export sub _GetPartitionTable$(Drive$) // lokale Variablen Definition local SystemInfo$ local ByteInHex$ local Result$ local i local Filename$ Filename$ = "sector.tmp" SystemInfo$ = "" ByteInHex$ = "" Result$ = "" // Array für die 64 Byte der Partitions- Tabelle dim PTable(64) // prüfen ob das angegebene Laufwerk vorhanden // und das richtige ist if right$(Drive$, 4) <> "/raw" then // sollten die letzten 4 Zeichen des Laufwerk- Strings // nicht "/raw" lauten, beenden und nichts zurückgeben return else // den ertsen Sektor der Festplatte mit "dd" in die temporäre // Datei "sector.tmp" schreiben SystemInfo$ = system$("dd if=" + Drive$ + " of=" + Filename$ + " count=1") // prüfen ob die erstellte Datei "sector.tmp" auch // vorhanden ist if not (system("test -f " + Filename$)) then // die Datei "sector.tmp" öffnen ... open Filename$ for reading as #1 // ... und an die entsprechende Stelle springen seek #1, 446 // alle 64 Byte der Partitions- Tabelle lesen for i = 1 to 64 // das Array PTable() nimmt alle Einträge der // Partitions- Tabelle auf PTable(i) = peek(#1) next i // die Datei "sector.tmp" wieder schließen close #1 // die einzelnen Werte aus der Partitions- Tabelle ermitteln // und zur Übergabe in einen String schreiben for i = 1 to 64 // den jeweiligen Hex- Wert jedes Bytes ermitteln ... ByteInHex$ = hex$(PTable(i)) // ... und prüfen ob dieser zweistellig ist, falls nicht ... if len(ByteInHex$) < 2 then // ... diesen zweistellig machen ByteInHex$ = "0" + ByteInHex$ endif // alle Bytes zu einem String zusammenfassen, durch "|" trennen ... // (durch die Trennung läßt sich der String später besser // weiterverarbeiten) Result$ = Result$ + ByteInHex$ + chr$(124) next i // ... und diesen zurückgeben return Result$ else // sollte die Datei "sector.tmp" aus irgendeinem Grund // nicht vorhanden sein, dann beenden und nichts zurückgeben return endif endif // die temporäre Datei "sector.tmp" wieder löschen SystemInput$ = system$("rm " + Filename$) end sub |
yab - Anzahl der Partitionen ermitteln
Donnerstag, 17. Mai 2012
Nachdem ich Euch in meinem letzten Beitrag "yab - den Inhalt der Partitions- Tabelle ermitteln" gezeigt habe wie man die Partitions- Tabelle einer Festplatte auslesen kann, möchte ich Euch heute ein praktisches Beispiel zeigen, was man mit den gewonnenen Informationen anstellen kann.
Ich möchte an dieser Stelle aber darauf hinweisen, das die hier gezeigten Beispiele nur mit "MBR- Partitions- Tabellen" funktionieren und auch nur mit den ersten vier, sprich primären, Partitionen. Erweiterte Partitionen werden an dieser Stelle (noch) nicht berücksichtigt.
Um nun die Anzahl der Partitionen zu ermitteln, verarbeiten wir die, aus der Sub- Routine "_GetPartitionTable$()" gewonnenen Informationen wie folgt.
Zunächst rufen wir die Sub- Routine "_GetPartitionTable$()" auf um die benötigten Informationen zu bekommen. Danach rufen wir die Sub- Routine "_GetPartitionCount()" und übergeben dieser die entsprechendenen Informationen als Parameter. Im Beispiel würde dies wie folgt aussehen.
| import GetPartitionTable import GetPartitionCount PartitionTable$ = _GetPartitionTable$("/dev/disk/ata/0/master/raw") print "Anzahl Partitionen: ", _GetPartitionCount(PartitionTable$) |
So, nachdem wir nun wissen wieviele Partitionen unsere Festplatte hat, hier noch der Quell- Text der Sub- Routine.
| // benötigt das Ergebnis aus _GetPartitionTable$() als Parameter export sub _GetPartitionCount(PartitionTable$) // lokale Variablen Definition local NumberOfTokens local i local PartitionCount PartitionCount = 0 // nimmt die einzelnenen Hex- Werte aus dem PartitionTable$ auf dim PTable$(1) // nimmt die einzelnen Dezimal- Werte aus PTable$() auf dim PTable(64) // den PartitionTable- String wieder auftrennen und die Hex- Werte // in PTable$ speichern NumberOfTokens = split(PartitionTable$, PTable$(), chr$(124)) // die gespeicherten Hex- Werte wieder in Dezimal- Werte umwandeln for i = 1 to NumberOfTokens - 1 PTable(i) = dec(PTable$(i)) next i // an diesen Stellen steht der Wert für den Partitionstyp, // ist dieser ungleich 0 dann ist eine Partition vorhanden for i = 0 to 3 // den jeweils 5. Wert aus den den 4 x 16 Byte lesen if PTable(5 + i * 16) <> 0 then // wenn ungleich 0, Zähler um eins erhöhen PartitionCount = PartitionCount + 1 endif next i // Ergebnis zurückliefern return PartitionCount end sub |
yab - den Typ einer Partition ermitteln
Dienstag, 22. Mai 2012
Aufbauend auf meine letzten beiden Beiträge "yab - den Inhalt der Partitions- Tabelle ermitteln..." und "yab - Anzahl der Partitionen ermitteln", möchte ich Euch heute zeigen, was wir mit den, aus dem Boot- Sektor, gewonnenen Daten noch so anstellen können.
Bereits beim Zählen der Partitionen habe ich das jeweils 5. Byte, des jeweils 16 Byte großen Eintrages, verwendet. Ist dieses ungleich Null, ist eine Partition vorhanden. Die untenstehende Sub- Routine greift ebenfalls auf dieses Byte zu und wertet es anhand einer Tabelle ("switch / case") aus.
Natürlich habe ich mir diese Tabelle nicht selbst ausgedacht, sie entspricht vielmehr der aktuellen Liste der "TU Eindhoven" welche Ihr hier einsehen könnt.
http://www.win.tue.nl/~aeb/partitions/partition_types-1.html
Zur Erklärung des Quell- Textes gibt es wie üblich nicht viel zu sagen, entsprechende Kommentare sind reichlich vorhanden. Allerdings habe ich lange überlegt den Quelltext anzuzeigen, da dieser sehr lang ist. Die teilweise etwas ungewöhnliche Notation ist lediglich der Anzeige geschuldet, da die Länge der einzelnen Zeilen sonst die Anzeige "gesprengt" hätte. Der Quelltext läßt sich dadurch erheblich verkürzen, indem man die einzelnen Zeilen wie folgt zusammenfaßt.
Anstelle von ...
| case 8: PType$ = "OS/2 (v1.0-1.3 only) / AIX boot partition / SplitDrive / " PType$ = PType$ + "Commodore DOS / DELL partition spanning multiple " PType$ = PType$ + "drives / QNX 1.x and 2.x ('qny')" break |
... könnte man auch
| case 8: PType$ = "OS/2 (v1.0-1.3 only) / AIX boot partition / SplitDrive / Commodore DOS / DELL partition spanning multiple drives / QNX 1.x and 2.x ('qny')": break |
schreiben. Somit würde sich der Quelltext, um eine nicht unerhebliche Zahl von Zeilen, verkürzen.
Der Aufruf der Sub- Routine erfolgt wieder in bekannter Manier, z.B. so. Benötigt wird, wie im Beispiel- Quelltext zu sehen ist, die Sub- Routine "GetPartitionTable" um den Inhalt des Boor- Sektors zu ermitteln. Als zweiter Parameter ist noch die Nummer der entsprechenden Partition anzugeben (gezählt wird hierbei ab 1).
| import GetPartitionTable import GetPartitionType PT$ = _GetPartitionTable$("/dev/disk/ata/0/master/raw") print "Type: ", _GetPartitionType$(PT$, 1) |
Und hier nun noch der Quelltext in voller Länge.
| export sub _GetPartitionType$(PartitionTable$, PartitionNumber) // lokale Variablen Definition local NumberOfTokens local i local PType$ PartitionCount = 0 // nimmt die einzelnenen Hex- Werte aus dem PartitionTable$ auf dim PTable$(1) // nimmt die einzelnen Dezimal- Werte aus PTable$() auf dim PTable(64) // den PartitionTable- String wieder auftrennen und die Hex- Werte // in PTable$ speichern NumberOfTokens = split(PartitionTable$, PTable$(), chr$(124)) // die gespeicherten Hex- Werte wieder in Dezimal- Werte umwandeln for i = 1 to NumberOfTokens - 1 PTable(i) = dec(PTable$(i)) next i // Position für den richtigen Wert berechnen PartitionType = PTable(5 + (PartitionNumber - 1) * 16) // Den entsprechenden Partitions- Typ zuweisen. // Die Angaben entsprechen der aktuellen Liste der // TU Eindhoven switch PartitionType case 0: PType$ = "empty" break case 1: PType$ = "DOS 12- bit FAT" break case 2: PType$ = "XENIX root" break case 3: PType$ = "XENIX /usr" break case 4: PType$ = "DOS 3.0+ 16- bit FAT (up to 32M)" break case 5: PType$ = "DOS 3.3+ Extended Partition" break case 6: PType$ = "DOS 3.31+ 16- bit FAT (over 32M)" break case 7: PType$ = "OS/2 IFS (HPFS) / Windows NT NTFS / exFAT / Advanced Linux" PType$ = PType$ +" / QNX 2.x pre- 1988" break case 8: PType$ = "OS/2 (v1.0-1.3 only) / AIX boot partition / SplitDrive / " PType$ = PType$ + "Commodore DOS / DELL partition spanning multiple " PType$ = PType$ + "drives / QNX 1.x and 2.x ('qny')" break case 9: PType$ = "AIX data partition / Coherent filesystem / QNX 1.x and " PType$ = PType$ + "2.x ('qnz')" break case 10: PType$ = "OS/2 Boot Manager / Coherent swap partition / OPUS" break case 11: PType$ = "WIN95 OSR2 FAT32" break case 12: PType$ = "WIN95 OSR FAT32, LBA- mapped" break case 13: PType$ = "unused" break case 14: PType$ = "WIN95 DOS 16- bit FAT, LBA- mapped" break case 15: PType$ = "WIN95 extended partition, LBA- mapped" break case 16: PType$ = "OPUS" break case 17: PType$ = "Hidden DOS 12- bit FAT / Leading Edge DOS 3.x logically " PType$ = PType$ + "sectored FAT" break case 18: PType$ = "Configuration/diagnostic partition" break case 19: PType$ = "unused" break case 20: PType$ = "Hidden DOS 16- bit FAT < 32M / AST DOS with logically " PType$ = PType$ + "sectored FAT" break case 21: PType$ = "unused" break case 22: PType$ = "Hidden DOS 16- bit FAT >= 32M" break case 23: PType$ = "Hidden IFS (HPFS)" break case 24: PType$ = "AST SmartSleep Partition" break case 25: PType$ = "unused" break case 26: PType$ = "unused" break case 27: PType$ = "Hidden WIN95 OSR2 FAT32" break case 28: PType$ = "Hidden WIN95 OSR2 FAT32, LBA- mapped" break case 29: PType$ = "unused" break case 30: PType$ = "Hidden WIN95 16- bit FAT, LBA- mapped" break case 31: PType$ = "unused" break case 32: PType$ = "unused" break case 33: PType$ = "reserved" break case 34: PType$ = "unused" break case 35: PType$ = "reserved" break case 36: PType$ = "NEC DOS 3.x" break case 37: PType$ = "unused" break case 38: PType$ = "reserved" break case 39: PType$ = "PQservice / Windows RE hidden Partition / MirOS Partition " PType$ = PType$ + "/ RouterBOOT Kernel Partition" break case 40: PType$ = "unused" break case 41: PType$ = "unused" break case 42: PType$ = "AtheOS File System (AFS)" break case 43: PType$ = "SyllableSecure (SylStor)" break case 44: PType$ = "unused" break case 45: PType$ = "unused" break case 46: PType$ = "unused" break case 47: PType$ = "unused" break case 48: PType$ = "unused" break case 49: PType$ = "reserved" break case 50: Type$ = "NOS" break case 51: PType$ = "reserved" break case 52: PType$ = "reserved" break case 53: PType$ = "JFS on OS/2 or eCS" break case 54: PType$ = "reserved" break case 55: PType$ = "unused" break case 56: PType$ = "THEOS Ver. 3.2 2gb Partition" break case 57: PType$ = "Plan 9 Partition / THEOS Ver. 4 spanned Partition" break case 58: PType$ = "THEOS Ver. 4 4gb Partition" break case 59: PType$ = "THEOS Ver. 4 extended Partition" break case 60: PType$ = "Partition Magic recovery Partition" break case 61: PType$ = "Hidden NetWare" break case 62: PType$ = "unused" break case 63: PType$ = "unused" break case 64: PType$ = "Venix 80286 / PICK" break case 65: PType$ = "Linux / MINIX (sharing disk with DRDOS) / Personal RISC " PType$ = PType$ + "Boot / PPC PReP (Power PC Reference Platform) Boot" break case 66: PType$ = "Linux Swap (sharing disk with DRDOS / SFS (Secure " PType$ = PType$ + "Filesystem) / Windows 2000 dynamic extended " PType$ = PType$ + "Partition marker" break case 67: PType$ = " Linux native (sharing disk with DRDOS)" break case 68: PType$ = "GoBack Partition" break case 69: PType$ = "Boot- US boot manager / Priam / EUMEL/Elan" break case 70: PType$ = "EUMEL/Elan" break case 71: PType$ = "EUMEL/Elan" break case 72: PType$ = "EUMEL/Elan" break case 73: PType$ = "unused" break case 74: PType$ = "Mark Aitchison's ALFS/THIN lightweight filesystem for " PTyoe$ = PType$ + "DOS / AdaOS Aquila (Withdrawn)" break case 75: PType$ = "unused" break case 76: PType$ = "Oberon partition" break case 77: PType$ = "QNX 4.x" break case 78: PType$ = "QNX 4.x 2nd part" break case 79: PType$ = "QNX 4.x 3rd part / Oberon partition" break case 80: PType$ = "OnTrack Disk Manager (older version) RO / Lynx RTOS / " PType$ = PType$ + "Native Oberon (alt)" break case 81: PType$ = "OnTrack Disk Manager / Novell" break case 82: PType$ = "CP/M / Microport SysV/AT" break case 83: PType$ = "Disk Manager 6.0 Aux3" break case 84: PType$ = "Disk manager 6.0 Dynamic Drive Overlay (DDO)" break case 85: PType$ = "EZ- Drive" break case 86: PType$ = "Golden Bow VFeature Partitioned Volume / DM converted to " PType$ = PType$ + "EZ- BIOS / AT&T MS- DOS 3.x logically sectored FAT" break case 87: PType$ = "DrivePro / VNDI Partition" break case 88: PType$ = "unused" break case 89: PType$ = "unused" break case 90: PType$ = "unused" break case 91: PType$ = "unused" break case 92: PType$ = "Priam EDisk" break case 93: PType$ = "unused" break case 94: PType$ = "unused" break case 95: PType$ = "unused" break case 96: PType$ = "unused" break case 97: PType$ = "SpeedStor" break case 98: PType$ = "unused" break case 99: PType$ = "Unix System V (SCO, ISC Unix, UnixWare, ...), Mach, GNU Hurd" break case 100: PType$ = "PC- ARMOUR protected partition / Novell Netware 286, 2.xx" break case 101: PType$ = "Novell Netware 386, 3.xx or 4.xx" break case 102: PType$ = "Novell Netware SMS Partition" break case 103: PType$ = "Novell" break case 104: PType$ = "Novell" break case 105: PType$ = "Novell Netware 5+, Novell Netware NSS Partition" break case 106: PType$ = "unused" break case 107: PType$ = "unused" break case 108: PType$ = "unused" break case 109: PType$ = "unused" break case 110: PType$ = "unused" break case 111: PType$ = "unused" break case 112: PType$ = "DiskSecure Multi- Boot" break case 113: PType$ = "reserved" break case 114: PType$ = "V7/x86" break case 115: PType$ = "reserved" break case 116: PType$ = "reserved / Scramdisk partition" break case 117: PType$ = "IBM PC/IX" break case 118: PType$ = "reserved" break case 119: PType$ = "M2FS/M2CS partition / VNDI Partition" break case 120: PType$ = "XOSL FS" break case 121: PType$ = "unused" break case 122: PType$ = "unused" break case 123: PType$ = "unused" break case 124: PType$ = "unused" break case 125: PType$ = "unused" break case 126: PType$ = "unused" break case 127: PType$ = "unused" break case 128: PType$ = "MINIX until 1.4a" break case 129: PType$ = "MINIX since 1.4b, early Linux / Mitac disk manager" break case 130: PType$ = "Prime / Solaris x86 / Linux swap" break case 131: PType$ = "Linux native partition" break case 132: PType$ = "OS/2 hidden C: drive / Hibernation partition" break case 133: PType$ = "Linux extended partition" break case 134: PType$ = "Old Linux RAID partition superblock / FAT16 volume set" break case 135: PType$ = "NTFS volume set" break case 136: PType$ = "Linux plaintext partition table" break case 137: PType$ = "unused" break case 138: PType$ = "Linux Kernel Partition (used by AiR- BOOT)" break case 139: PType$ = "Legacy Fault Tolerant FAT32 volume" break case 140: PType$ = "Legacy Fault Tolerant FAT32 volume using BIOS extd INT 13h" break case 141: PType$ = "Free FDISK 0.96+ hidden Primary DOS FAT12 partition" break case 142: PType$ = "Linux Logical Volume Manager partition" break case 143: PType$ = "unused" break case 144: PType$ = "Free FDISK 0.96+ hidden Primary DOS FAT16 partition" break case 145: PType$ = "Free FDISK 0.96+ hidden DOS extended partition" break case 146: PType$ = "Free FDISK 0.96+ hidden Primary DOS large FAT16 partition" break case 147: PType$ = "Hidden Linux native partition / Amoeba" break case 148: PType$ = "Amoeba bad block table" break case 149: PType$ = "MIT EXOPC native partition" break case 150: PType$ = "CHRP ISO- 9660 filesystem" break case 151: PType$ = "Free FDISK 0.96+ hidden Primary DOS FAT32 partition" break case 152: PType$ = "Free FDISK 0.96+ hidden Primary DOS FAT32 partition (LBA) / " PType$ = PType$ + "Datalight ROM- DOS Super- Block Partition" break case 153: PType$ = "DCE376 logical drive" break case 154: PType$ = "Free FDISK 0.96+ hidden Primary DOS FAT16 partition (LBA)" break case 155: PType$ = "Free FDISK 0.96+ hidden DOS extended partition (LBA)" break case 156: PType$ = "unused" break case 157: PType$ = "unused" break case 158: PType$ = "ForthOS partition" break case 159: PType$ = "BSD/OS" break case 160: PType$ = "Laptop hibernation partition" break case 161: PType$ = "Laptop hibernation partition / HP Volume Expansion (SpeedStor" PType$ = PType$ + " variant)" break case 162: PType$ = "unused" break case 163: PType$ = "HP Volume Expansion (SpeedStor variant)" break case 164: PType$ = "HP Volume Expansion (SpeedStor variant)" break case 165: PType$ = "BSD/386, 386BSD, NetBSD, FreeBSD" break case 166: PType$ = "OpenBSD / HP Volume Expansion (SpeedStor variant)" break case 167: PType$ = "NeXTStep" break case 168: PType$ = "Mac OS- X" break case 169: PType$ = "NetBSD" break case 170: PType$ = "Olivetti Fat 12 1.44MB Service Partition" break case 171: PType$ = "Mac OS- X Boot partition / GO! partition" break case 172: PType$ = "unused" break case 173: PType$ = "unused" break case 174: PType$ = "ShagOS filesystem" break case 175: PType$ = "ShagOS swap partition / MacOS X HFS" break case 176: PType$ = "BootStar Dummy" break case 177: PType$ = "HP Volume Expansion (SpeedStor variant) / QNX Neutrino " PType$ = PType$ + "Power- Safe filesystem" break case 178: PType$ = "QNX Neutrino Power- Safe filesystem" break case 179: PType$ = "HP Volume Expansion (SpeedStor variant) / QNX Neutrino " PType$ = PType$ + "Power- Safe filesystem" break case 180: PType$ = " HP Volume Expansion (SpeedStor variant)" break case 181: PType$ = "unused" break case 182: PType$ = "HP Volume Expansion (SpeedStor variant) / Corrupted Windows" PType$ = PType$ + " NT mirror set (master), FAT16 file system" break case 183: PType$ = "Corrupted Windows NT mirror set (master), NTFS file system " PType$ = PType$ + "/ BSDI BSD/386 filesystem" break case 184: PType$ = "BSDI BSD/386 swap partition" break case 185: PType$ = "unused" break case 186: PType$ = "unused" break case 187: PType$ = "Boot Wizard hidden" break case 188: PType$ = "Acronis backup partition" break case 189: PType$ = "BonnyDOS/286" break case 190: PType$ = "Solaris 8 boot partition" break case 191: PType$ = "New Solaris x86 partition" break case 192: PType$ = "CTOS / REAL/32 secure small partition / NTFT Partition / " PType$ = PType$ + "DR- DOS/Novell DOS secured partition" break case 193: PType$ = "DR-DOS/secured (FAT12)" break case 194: PType$ = "Hidden Linux" break case 195: PType$ = "Hidden Linux swap" break case 196: PType$ = "DR-DOS/secured (FAT16, <32M)" break case 197: PType$ = "DR-DOS/secured (extended)" break case 198: PType$ = "DR-DOS/secured FAT16, >=32M) / Windows NT corrupted FAT16 " PType$ = PType$ + "volume/stripe set" break case 199: PType$ = "Windows NT corrupted NTFS volume/stripe set / Syrinx boot" break case 200: PType$ = "reserved fpr DR- DOS 8.0x" break case 201: PType$ = "reserved fpr DR- DOS 8.0x" break case 202: PType$ = "reserved fpr DR- DOS 8.0x" break case 203: PType$ = "DR- DOS 7.04+ secured FAT32 (CHS)" break case 204: PType$ = "DR- DOS 7.04+ secured FAT32 (LBA)" break case 205: PType$ = "CTOS Memdump" break case 206: PType$ = "DR- DOS 7.04+ FAT16 (LBA)" break case 207: PType$ = "DR- DOS 7.04+ secured EXT DOS (LBA)" break case 208: PType$ = "REAL/32 secure big partition / Mutiuser DOS secured partition" break case 209: PType$ = "Old Multiuser DOS secured FAT12" break case 210: PType$ = "unused" break case 211: PType$ = "unused" break case 212: PType$ = "Old Multiuser DOS secured FAT16 < 32M" break case 213: PType$ = "Old Multiuser DOS secured extended partition" break case 214: PType$ = "Old Multiuser DOS secured FAT16 >= 32M" break case 215: PType$ = "unused" break case 216: PType$ = "CP/M- 86" break case 217: PType$ = "unused" break case 218: PType$ = "Non- FS Data / Powercopy Backup" break case 219: PType$ = "Digital Research CP/M, Concurrent CP/M, Concurrent DOS / CTOS " PType$ = PType$ + "(Convergent Technologies OS- Unisys / KDG Telemetry " PType$ = PType$ + "SCPU boot" break case 220: PType$ = "unused" break case 221: PType$ = "Hidden CTOS Memdump" break case 222: PType$ = "Dell PowerEdge Server utilities (FAT fs)" break case 223: PType$ = "DG/UX virtual disk manager partition / BootIt EMBRM" break case 224: PType$ = "reserved by STMicroelectronics for a filesystem called ST AVFS" break case 225: PType$ = "DOS access or SpeedStor 12- bit FAT extended partition" break case 226: PType$ = "unused" break case 227: PType$ = "DOS R/O or SpeedStor" break case 228: PType$ = "SpeedStor 16- bit FAT extended partition < 1024 cyl." break case 229: PType$ = "Tandy MS- DOS with logically sectored FAT" break case 230: PType$ = "Storage Dimensions SpeedStor" break case 231: PType$ = "unused" break case 232: PType$ = "LUKS" break case 233: PType$ = "unused" break case 234: PType$ = "unused" break case 235: PType$ = "BeOS BFS" break case 236: PType$ = "SkyOS SkyFS" break case 237: PType$ = "unused" break case 238: PType$ = "Indication that this legacy MBR is followed by an EFI" PType$ = PType$ + " header" break case 239: PType$ = "Partition that contains an EFI file system" break case 240: PType$ = "Linux/PA- RISC boot loader" break case 241: PType$ = "Storage Dimensions SpeedStor" break case 242: PType$ = "DOS 3.3+ secondary partition" break case 243: PType$ = "reserved" break case 244: PType$ = "SpeedStor large partition / Prologue single- volume partition" break case 245: PType$ = "Prologue multi- volume partition" break case 246: PType$ = "Storage Dimensions SpeedStor" break case 247: PType$ = "DDRdrive Solid State File System" break case 248: PType$ = "unused" break case 249: PType$ = "pCache" break case 250: PType$ = "Bochs" break case 251: PType$ = "VMware File System partition" break case 252: PType$ = "VMware Swap partition" break case 253: PType$ = "Linux RAID partition with autodetect using persistent superblock" break case 254: PType$ = "SpeedStor > 1024 cyl. / LANstep / IBM PS/2 IML (Initial Microcode" PType$ = PType$ + " Load) partition, located at the end of the disk / " PType$ = PType$ + "Windows NT Disk Administrator hidden partition / Linux " PType$ = PType$ + "Logical Volume Manager partition (old)" break case 255: PType$ = "XENIX Bad Block Table" break end switch // Partitions- Typ zurückgeben return PType$ end sub |
yab - die Größe einer Partition ermitteln
Freitag, 1. Juni 2012
Abschließend zum Thema "yab und die Partitionstabelle" möchte ich Euch heute noch ein letztes Beispiel geben, was man mit den gewonnenen Informationen aus der Sub- Routine "GetPartitionTable" noch so anstellen kann.
Wie wir bereits gelernt haben, ist die Partitionstabelle (bei MBR- Datenträgern) 64 Byte groß ist, und an Position 446 des ersten Sektors beginnt. Die Partitionstabelle hat prinzipiell 4 Einträge zu je 16 Byte. Die letzten 4 Byte eines jeden Eintrages sind im heutigen Beispiel von Interesse. Diese 4 Byte enthalten die Größe der entsprechenden Partition in Sektoren. Multipliziert man diese mit 512 (Byte pro Sektor) erhält man die Größe der Partition in Byte.
Das folgende, kleine Beispiel soll dies veranschaulichen. Es ist dabei darauf zu achten das die angesprochenen 4 Byte in umgekehrter Reichenfolge zu verarbeiten sind. Zu Funktion der Sub- Routine wird ebenfalls wieder, wie im Beispiel zu sehen, die Sub- Routine "GetPartitionTable" benötigt. Selbstverständlich habe ich auch diesen Quelltext wieder mit reichlich Kommentaren gespieckt, sodaß auch hier keine Frage offen bleiben sollte.
Der Aufruf der Sub- Routine erfolgt dann wieder in folgender Form. Als Parameter benötigen wir das Ergebnis aus "GetPartitionTable" und die Partition von welcher der Größe bestimmt werden soll (gezählt wird wieder ab 1).
Beispiel
| import GetPartitionTable import GetPartitionSize PT$ = _GetPartitionTable$("/dev/disk/ata/0/master/raw") print "Partitionsgröße (in Byte): ", _GetPartitionSize(PT$, 1) |
Und hier der Quelltext für die Sub- Routine.
| export sub _GetPartitionSize(PartitionTable$, PartitionNumber) // lokale Variablen Definition local NumberOfTokens local PartitionSize // nimmt die einzelnenen Hex- Werte aus dem PartitionTable$ auf dim PTable$(1) // nimmt die einzelnen Dezimal- Werte aus PTable$() auf dim PTable(64) // den PartitionTable- String wieder auftrennen und die Hex- Werte // in PTable$ speichern NumberOfTokens = split(PartitionTable$, PTable$(), chr$(124)) // in diesen vier Bytes steht die Anzahl der Sektoren der ent- // sprechenden Partition S1$ = PTable$(13 + (PartitionNumber - 1) * 16) S2$ = PTable$(14 + (PartitionNumber - 1) * 16) S3$ = PTable$(15 + (PartitionNumber - 1) * 16) S4$ = PTable$(16 + (PartitionNumber - 1) * 16) // die Bytes werden in umgekehrter Reihenfolge zu einem HEX- Wert // zusammengefaßt ... SectorsInHex$ = S4$ + S3$ + S2$ + S1$ // ... und in eine Dezimalzahl umgewandelt, daraus ergibt sich die // Anzahl der Sektoren pro Partition ... Sectors = dec(SectorsInHex$) // ... multipliziert man diese nun mit 512 (Byte per Sektor), erhält // man die Größe der Partition in Byte PartitionSize = Sectors * 512 // Ergebnis zurückgeben return PartitionSize end sub |
yab - die Anzahl der USB- Controller ermitteln
Samstag, 16. Juni 2012
Nachdem ich in der Vergangenheit schon einige Routinen zum Auslesen von Hardware- Informationen vorgestellt habe, ist mir nun ein weiteres, interessantes Thema eingefallen. So möchte ich Euch in den nächsten Tagen und Wochen zeigen wie man mit "yab" Informationen zu USB- Controllern und - Geräten auslesen kann. Hilfe bekommen wir dabei wieder von der Kommandozeile und insbesondere von dem Befehl "listusb".
Als erstes möchte ich Euch zeigen wie man die Anzahl der USB- Controller in einem System bestimmen kann. Ruft man im "Terminal" nun den Kommandozeilen- Befehl "listusb" auf, listet dieser alle USB- Controller und angeschlossenen Geräte auf. Für dieses Beispiel ist dies jedoch viel zu viel und so filtern wir die Ausgabe ein wenig mit dem Befehl "grep". Der folgende Befehl gibt dann nur die USB- Hub's aus. Pro USB- Controller gibt es einen USB- Hub, und somit ist die Anzahl der USB- Hub's gleich der Anzahl der vorhandenen USB- Controller.
| listusb | grep "hub" |
Um das Ganze in "yab" abzubilden kann untenstehende Routine verwendet werden. Parameter müssen in diesem Fall nicht übergeben werden und das Ergebnis ist einfach eine Zahl welche die Anzahl der USB- Controller im System wiedergibt.
Der Aufruf der Sub- Routine kann dabei wie folgt geschehen.
| print "USB- Controller: ", _GetUSBControllerCount() |
| export sub _GetUSBControllerCount() // lokale Variablen- Definition local SystemInput$ local NumberOfTokens dim Line$(1) // Den Befehl "listusb" ausführen und nach "hub" filtern, // so werden nur die USB- Hub's in die Liste aufgenommen. SystemInput$ = system$("listusb | grep hub") // SystemInput$ in einzelne Zeilen zerlegen, die Anzahl // der Zeilen ist gleich der Anzahl der USB- Controller. NumberOfTokens = split(SystemInput$, Line$(), chr$(10)) return NumberOfTokens - 1 end sub |
yab - Anzahl der angeschlossenen USB- Geräte je USB- Controller ermitteln
Donnerstag, 21. Juni 2012
In den letzten beiden Posts "yab - die Anzahl der USB- Controller ermitteln" und "yab - Anzahl der angeschlossenen USB- Geräte ermitteln" habe ich Euch bereits gezeigt wie man die Anzahl der USB- Controller bzw. die Anzahl der angeschlossenen USB- Geräte ermitteln kann. Im heutigen Post möchte ich Euch zeigen, wie man die Anzahl angeschlossener USB- Geräte je USB- Controller ermitteln kann.
Zu diesem Zweck bedienen wir uns wieder bei der Sub- Routine "GetUSBControllerCount.yab". Mit dem Ergebnis aus dieser Sub- Routine bauen wir uns den Device- Pfad zusammen und rufen diesen zusammen mit dem Kommandozeilen- Befehl "listusb" auf. Der Zähler für die USB- Geräte wird dabei solange erhöht bis das Ergebnis die Zeichenkette "Cannot open USB device:" enthält. Ist dies der Fall, ist kein weiteres USB- Gerät an diesem USB- Controller verfügbar und die Verarbeitung wird abgebrochen.
Als Parameter für die Sub- Routine wird die Nummer des entsprechenden USB- Controller übergeben. Folgendes Beispiel sowie die Sub- Routine selbst, sollen dies veranschaulichen. Zur einwandfreien Funktion ist ebenfalls wieder die Sub- Routine "GetUSBControllerCount.yab" erforderlich. Gewürzt mit jeder Menge Kommentaren sollte sich die Sub- Routine prinzipiell von selbst erklären.
Beispiel
| import GetUSBControllerCount print "Anzahl der USB- Geräte je USB- COntroller:" for i = 1 to _GetUSBControllerCount() Devices$ = str$(_GetUSBControllerDevicesCount()) print "USB- Controller (" + str$(i) + ") = " + Devices$ next i |
Sub- Routine
| export sub _GetUSBControllerDevicesCount(ControllerNumber) // lokale Variablen- Definition local SystemInput$ local Device$ local NoDevice dim Line$(1) NoDevice = false // den Pfad zum entsprechenden USB- Device "zusammenbauen" Device$ = "/dev/bus/usb/" + str$(ControllerNumber) + "/" while (NoDevice = false) // Den Befehl "listusb -v" mit dem generierten Device- Pfad // aufrufen und Ergebnis in SystemInput$ speichern. SystemInput$ = system$("listusb " + Device$ + str$(Counter)) // Prüfen ob die Ausgabe den String "Cannot open USB device:" // enthält, wenn ja ist kein weiteres Device verfügbar, Abbruch. if not instr(SystemInput$, "Cannot open USB device:") then Counter = Counter + 1 else // wenn kein weiteres USB- Gerät gefunden wird, abbrechen NoDevice = true break endif wend // Ergebnis zurückgeben return Counter end sub |
yab - den Typ eines USB- Controllers herausfinden
Freitag, 6. Juli 2012
Nachdem ich Euch in den letzten Tage und Wochen gezeigt habe, wie man erfolgreich Informationen über die USB- Schnittstelle herausfinden kann, möchte ich das Ganze heute noch ein wenig erweitern. Nachdem wir bereits wissen wie viele USB- Schnittstellen im System stecken und wie viele Geräte daran angeschlossen sind, möchte ich Euch noch zeigen an welchem Typ- USB- Controller diese Geräte angeschlossen sind.
Zu diesem Zweck bedienen wir und der Sub- Routine "GetUSBControllerType.yab" welche am Ende dieses Beitrags zu finden ist. Auch in diesem Fall bedienen wir und wieder bei dem Kommandozeilen- Befehl "listusb" in Verbindung mit dem Parameter "-v". Dazu kommt noch ein wenig Parsen hier und ein bisschen Parsen da und schon haben wir das gewünschte Ergebnis.
Als Parameter übergeben wir der Sub- Routine die Nummer des entsprechenden USB-Controllers. Als Ergebnis erhalten wir dann die Bezeichnung (den Typ) des jeweiligen USB- Controllers (OHCI, EHCI, UHCI, ...). Der Quelltext ist wieder mit vielen Kommentaren gespickt und sollte sich prinzipiell von selbst erklären.
Beispiel
| import GetUSBControllerCount for i = 0 to _GetUSBControllerCount() print "USB- Controller (" + str$(i) + "): " + _GetUSBControllerType$(i) next i |
Sub- Routine
| export sub _GetUSBControllerType$(ControllerNumber) // lokale Variablen- Definition local SystemInput$ local NumberOfTokens local Device$ local Result$ local i dim Line$(1) // den Pfad zum entsprechenden USB- Device "zusammenbauen" Device$ = "/dev/bus/usb/" + str$(ControllerNumber) + "/hub" // Den Befehl "listusb -v" mit dem generierten Device- Pfad // aufrufen und Ergebnis in SystemInput$ speichern. SystemInput$ = system$("listusb -v " + Device$) // Das Ergebnis in einzelne Zeilen zerlegen ... NumberOfTokens = split(SystemInput$, Line$(), chr$(10)) // ... und nach der Zeile mit "Product String" suchen for i = 1 to NumberOfTokens // wenn der gesuchte String gefunden wurde ... if instr(Line$(i), "Product String") then // ... die gewünschten Zeichen ausschneiden ... Result$ = mid$(Line$(i), instr(Line$(i), chr$(34))) // ... und von diesen das linke '"'- Zeichen entfernen if left$(Result$, 1) = chr$(34) then Result$ = mid$(Result$, 2) endif // ... und auch das rechte '"'- Zeichen entfernen if right$(Result$, 1) = chr$(34) then Result$ = left$(Result$, len(Result$) - 1) endif endif next i // das Ergebnis zurückgeben return Result$ end sub |
Scripting - grep, grep, hurra
Mittwoch, 11. Juli 2012
Hin und wieder kommt es vor das man sich selbst gegen die Stirn schlägt und denkt, warum hast du da nicht früher dran gedacht. So erging es mir vor ein paar Tagen als ich mir mal wieder einen Quelltext angesehen habe und feststellen musste, warum einfach wenn's auch kompliziert geht.
Lange Rede kurzer Sinn, ich spreche hier von meinen letzten Beiträgen zum Thema USB- Schnittstelle, insbesondere von "yab - Anzahl der angeschlossenen USB- Geräte ermitteln". Man muss es gar nicht so umständlich machen, erst alle USB- Hub's ermitteln, dann alle USB- Geräte ermitteln und dann das Ganze subtrahieren. Es geht auch deutlich einfacher. Die einzelnen, untenstehenden Beispiele sollen dies einmal genauer zeigen. Sie sind bewusst nicht in "yab" geschrieben sondern allesamt über die Kommandozeile eingegeben.
Gibt man nun, in einem Terminal, folgende Zeile ein, erhält man nachstehendes Ergebnis.
| listusb |
Wie ich es in meinen "yab"- Routinen bereits gezeigt habe, kann man nun die einzelnen USB- Hub's aus diesem Wust an Informationen wie folgt herausfiltern.
| listusb | grep hub |
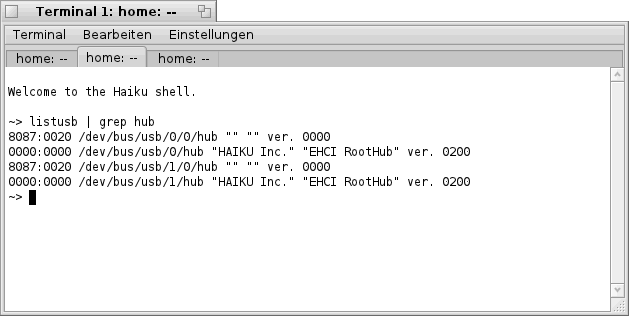
Um nun herauszubekommen welche Geräte keine USB- Hub's sind, bzw. die Anzahl der an USB angeschlossenen Geräte herauszubekommen, sollte man vielleicht besser so vorgehen.
| listusb | grep hub -v |
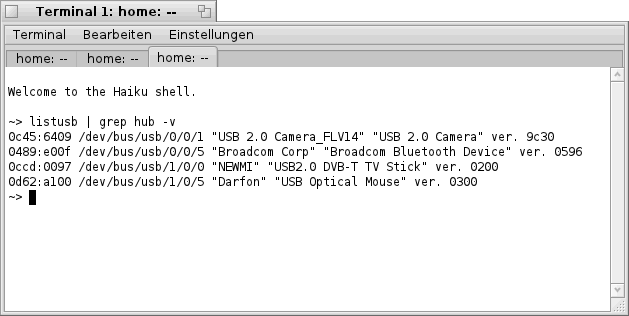
Ich hatte nämlich total vergessen, bzw. gar nicht daran gedacht, das der "grep"- Befehl ja auch Parameter, in diesem Fall "-v", haben könnte und so bin ich dann etwas zu spät doch noch darüber gestolpert.
zurück zur Übersicht
yab - ein (sicheres) Passwort generieren
Sonntag, 5. August 2012
So, nach der ganzen Hardwareausleserei mal wieder ein wenig "normale" yab- Kost.
Das Thema Sicherheit wird aktuell immer wichtiger und so habe ich mich hingesetzt, einen etwas älteren Quellcode herausgekramt und diesen gehörig aufpoliert. Herausgekommen ist dabei eine nette, kleine Routine zum generieren von Passwörtern.
Für das Paswort können dabei unterschiedliche Kombinationen aus Kleinbuchstaben, Großbuchstaben, Zahlen und Sonderzeichen gewählt werden. Die Länge des Passworts ist beliebig, sollte in der heutigen Zeit jedoch nicht zu kurz gewählt werden.
Dies sind dann auch schon die beiden Parameter welche an die Sub- Routine übergeben werden müssen (Pattern = aus welchen Zeichen soll das Passwort bestehen und Length = Länge des Passworts). Der Wert für Pattern muß eine Zahl im Bereich von 1 - 15 sein, andernfalls quittiert die Routine ihren Dienst mit der Meldung "Es sind nur Werte von 1 - 15 erlaubt!". Die verwendeten Strings für Klein- und Großbuchstaben sowie Zahlen sind soweit klar geregelt. Der String für die Sonderzeichen kann prinzipiell noch erweitert werden. Hier sollte man aber etwas aufpassen, da "yab" aus einigen Sonderzeichen 2- Byte- Character macht (z.B. beim "§"- Zeichen) können hier unschöne Fehler auftreten.
Wie üblich ist auch dieser Quellcode wieder ausreichend mit Kommentaren gewürzt und sollte keine Fragen offen lassen. Das untenstehende Beispiel generiert 10 Passwörter mit Klein- und Großbuchstaben, Zahlen und Sonderzeichen sowie einer Länge von 32 Zeichen.
Beispiel
| import GeneratePassword for i = 1 to 10 Pattern = 15 Length = 32 pwd$ = _GeneratePassword$(Pattern, Length) print "Passwort " + str$(i) + ": " + pwd$ next i |
Sub- Routine
| // ---------------------------------------------------------------------- // _GeneratePassword$(Pattern, Length) // // Pattern: Bestimmt aus welchen Zeichen das Passwort bestehen soll. Der // Wert ist binär aufgebaut: // // 0 = nicht möglich (es wären keine Zeichen ausgewählt) // 1 = Großbuchstaben // 2 = Kleinbuchstaben // 3 = Kleinbuchstaben & Großbuchstaben // 4 = Zahlen // 5 = Zahlen & Großbuchstaben // 6 = Zahlen & Kleinbuchstaben // 7 = Zahlen & Kleinbuchstaben & Großbuchstaben // 8 = Sonderzeichen // 9 = Sonderzeichen & Großbuchstaben // 10 = Sonderzeichen & Klein$dbuchstaben // 11 = Sonderzeichen & Kleinbuchstaben & Großbuchstaben // 12 = Sonderzeichen & Zahlen // 13 = Sonderzeichen & Zahlen & Großbuchstaben // 14 = Sonderzeichen & Zahlen & Kleinbuchstaben // 15 = Sonderzeichen & Zahlen & Kleinbuchstaben & Großbuchstaben // // Lenght: Bestimmt aus wievielen Zeichen das Passwort bestehen soll. Es // sind maximal 256 Zeichen erlaubt // // ---------------------------------------------------------------------- export sub _GeneratePassword$(Pattern, Length) // lokale Variablen- Definitionen local Grossbuchstaben$ local Kleinbuchstaben$ local Zahlen$ local Sonderzeichen$ local Generate$ local Position local Password$ local i Grossbuchstaben$ = "ABCDEFGHIJKLMNOPQRSTUVWXYZ" Kleinbuchstaben$ = "abcdefghijklmnopqrstuvwxyz" Zahlen$ = "0123456789" Sonderzeichen$ = "!$%&/()=?,.;:#'+*<>-_" Generate$ = "" Password$ = "" // Prüfen ob für "Pattern" ein gültiger Wert angegeben wurde. // Wenn nicht abbrechen. if (Pattern < 1) or (Pattern > 15) then return "Es sind nur Werte von 1 - 15 erlaubt!" endif // einen kleinen Moment warten um bei zu schneller Folge- Aufrufe // nicht zweimal das gleiche Passwort zu erhalten sleep ran() / 10 switch Pattern case 1 Generate$ = Grossbuchstaben$ break case 2 Generate$ = Kleinbuchstaben$ break case 3 Generate$ = Kleinbuchstaben$ + Grossbuchstaben$ break case 4 Generate$ = Zahlen$ break case 5 Generate$ = Zahlen$ + Grossbuchstaben$ break case 6 Generate$ = Zahlen$ + Kleinbuchstaben$ break case 7 Generate$ = Zahlen$ + Kleinbuchstaben$ + Grossbuchstaben$ break case 8 Generate$ = Sonderzeichen$ break case 9 Generate$ = Sonderzeichen$ + Grossbuchstaben$ break case 10 Generate$ = Sonderzeichen$ + Kleinbuchstaben$ break case 11 Generate$ = Sonderzeichen$ + Kleinbuchstaben$ + Grossbuchstaben$ break case 12 Generate$ = Sonderzeichen$ + Zahlen$ break case 13 Generate$ = Sonderzeichen$ + Zahlen$ + Grossbuchstaben$ break case 14 Generate$ = Sonderzeichen$ + Zahlen$ + Kleinbuchstaben$ break case 15 Generate$ = Sonderzeichen$ + Zahlen$ + Kleinbuchstaben$ + Grossbuchstaben$ break end switch // für die Länge des Passworts jeweils ein Zeichen aus dem Generate$ holen for i = 1 to Length Position = int(ran(len(Generate$)) + 1) Password$ = Password$ + mid$(Generate$, Position, 1) next i return Password$ end sub |
yab - ein wenig String- Manipulation
Mittwoch, 15. August 2012
Wie Ihr sicherlich schon bemerkt habt, kommt in letzter Zeit nicht mehr soviel zum Thema "yab" von mir. Dies liegt nicht etwa daran, dass ich keine Lust mehr habe, sondern daran, dass ich im Moment recht wenig freie Zeit habe.
Dennoch habe ich mich in einem ruhigen Moment hingesetzt und zwei kleine Sub- Routinen in Sachen String- Manipulation ausgearbeitet.
Die erste Sub- Routine stellt eine Funktion zur Verfügung, welche einen Teil- String, beginnend mit dem ersten Vorkommen des angegebenen Zeichens bis zum Ende des Strings zurückgibt. Klingt irgendwie kompliziert, ist es aber nicht, wie Ihr im Beispiel unten sehen werdet.
Die zweite Sub- Routine stellt hingegen eine Funktion zur Verfügung, welche einen Teil- String, vom Angang des übergebenen Strings bis zum ersten Vorkommen des angegebenen Zeichens zurück gibt. Auch hier zeigt das untenstehende Beispiel was genau gemeint ist.
Beispiel 1
| import GetStringFromCharacter print _GetStringFromCharacter$("Hallo Welt", "W") |
Ergebnis: "Welt"
Beispiel 2
| import GetStringToCharacter print _GetStringToCharacter$("Hallo Welt", "W") |
Ergebnis: "Hallo W"
Sub- Routine 1 (GetStringFromCharacter)
| export sub _GetStringFromCharacter$(String$, Character$) // lokale Variablen- Definition local i local Result$ // Für jedes Zeichen des Strings einmal nachsehen for i = 1 to len(String$) // Wenn das Zeichen gefunden wurde... if mid$(String$, i, 1) = Character$ then // ... den Rest des Strings als Ergebnis zurückgeben ... Result$ = right$(String$, len(String$) - (i - 1)) // ... und abbrechen. break else // Wenn das Zeichen nicht gefunden wurde, // einen leeren String zurückgeben Result$ = "" endif next i // Erbegnis zurückgeben return Result$ end sub |
Sub- Routine 2 (GetStringToCharacter)
| export sub _GetStringToCharacter$(String$, Character$) // lokale Variablen- Definition local i local Result$ // Für jedes Zeichen des Strings einmal nachsehen for i = 1 to len(String$) // Wenn das Zeichen gefunden wurde... if mid$(String$, i, 1) = Character$ then // ... den String vom Anfang bis zum gewählten // Zeichen zurückgeben ... Result$ = left$(String$, i) // ... und abbrechen. break else // Wenn das Zeichen nicht gefunden wurde, // einen leeren String zurückgeben Result$ = "" endif next i // Erbegnis zurückgeben return Result$ end sub |
Scripting - Lautstärke mit System
Donnerstag, 30. August 2012
Wie der Titel dieses Beitrages schon vermuten läßt, geht es heute darum die System- Lautstärke über das Terminal zu beeinflussen. Für diesen Zweck stell Haiku den Kommandozeilen- Befehl "setvolume" zur Verfügung. Ruft man diesen Befehl einmal im Terminal auf, zeigt sich folgendes Bild.
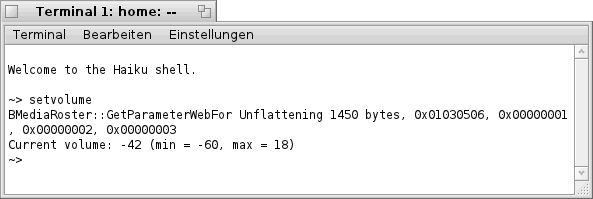
Zu sehen sind ein paar seltsame Meldungen und einige kryptische Zahlen- Kolonnen. In der dritten Zeile wird es dann jedoch interessant für uns, denn dort ist folgendes zu lesen "Current volume:". Die danach stehende Zahl repräsentiert dabei die aktuelle Lautstärke- Einstellung und, diese läßt sich natürlich auch verändern.
Weiterhin ist zu sehen, dass sich die Einstellungen für die Lautstärke im Bereich von -60 bis 18 bewegen können/dürfen. Ruft man nun den Kommandozeilen- Befehl "setvolume" mit einem entsprechenden Parameter auf, können wir die System- Lautstärke damit verändern.
Beispiel
| setvolume 0 |
Das folgende Bild zeigt die Auswirkung des oben angegebenen Beispiels. Die Zahl "0" stellt dabei die standard/normal Einstellung des Systems dar.
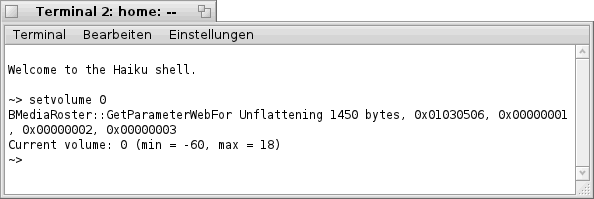
Das untenstehende, kleine Shell- Script zeigt dies noch einmal etwas anschaulicher, indem es die System- Lautstärke auf ganz leise stellt und dann bis zum Maximum "aufdreht". Anschließend wird die Lautstärke wieder auf ganz leise eingestellt und am Schluß wieder auf "normal". Viel Spaß beim Tüfteln.
| #!/bin/sh COUNT=-60 until [ $COUNT -gt 18 ]; do setvolume $COUNT let COUNT=COUNT+1 done COUNT=18 while [ $COUNT -gt -60 ]; do setvolume $COUNT let COUNT=COUNT-1 done setvolume 0 |
Test - Software "yabConceptCreator"
Sonntag, 9. September 2012
Der neue "yabConceptCreator" stellt die konsequente Weiterentwicklung der bisherigen, ebenfalls in "yab" entwickelten, "yabIDE" dar. Das Benutzer- Interface ist ein deutliches Stück "schöner", eleganter, Benutzerfreundlicher und einfach erwachsener geworden. Des Weiteren ist der Funktionsumfang enorm gestiegen und alles fühlt sich irgendwie "flüssiger" und moderner an.
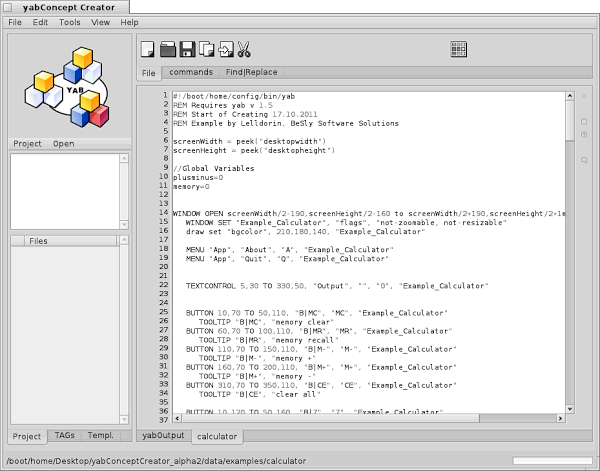
Die Installation des "ConceptCreator" geht dabei spielend einfach von der Hand, denn sie beschränkt sich auf das Herunterladen und das Entpacken des *.zip- Files. Wer will kann es danach noch an einen Ort seiner Wahl kopieren und sich auch eine Verknüpfung im Startmenü anlegen. Alles was Ihr für die Installation und den Betrieb des "yabConveptCreator" benötigt, findet Ihr am Ende dieses Artikels.
Nach dem Start des "ConceptCreator" sieht die neue Oberfläche zuerst einmal etwas befremdlich aus, da diese stark überarbeitet wurde. Nach einer kurzen Eingewöhnungs- Phase gehört dieses Gefühl jedoch schnell der Vergangenheit an und die Neugier fordert ein sofortiges Ausprobieren der vielen neuen Funktionen.
Eine meiner persönlichen Favoriten ist die neu hinzugekommene Möglichkeit, die Befehle zum Erstellen der verschiedenen "Haiku- GUI- Elemente", nun direkt per Mouse- Klick in das jeweilige Programm einfügen zu können. Zugegeben, dies ist noch kein visuelles Programmieren a'la Delphi (einige von Euch erinnern sich vielleicht noch), aber mir persönlich hilft es ungemein und das Nachschlagen in den Hilfe- Seiten ist deutlich weniger geworden.
Einen ebenfalls professionelleren Eindruck vermitteln die vielen kleinen, ebenfalls neu hinzugekommenen Dialoge, sei es eine Abfrage zum Speichern, die Neuanlage eines Projektes, das integrierte "Tipp"- Fenster oder auch die "Color- Table". Alle samt helfen dabei die neue "yabIDE" weiter voran zu bringen.
Zu den weiteren Fortschritten zählt auch die Integration verschiedener Tools wie z.B. "Bin Tools Help", "ASCII- Tabelle", "Open Terminal" und die Möglichkeit, Quelltexte nach "PDF" oder "HTML" exportieren zu können. Dies alles zeigt einmal mehr den Wunsch der Entwickler mehr Professionalität in die "yab"- Programmierung unter Haiku zu bringen. Bedenkt man dabei, dass die gesamte Entwicklungsumgebung mit "yab" realisiert wurde, stellt sich durchaus ein Gefühl des Erstaunens ein.
Die mitgelieferten "Examples" runden das bereits gute Gesamtbild der neuen IDE ebenso ab wie die Möglichkeit nun endlich auch selbst Programm- Vorlagen mit der Funktion "Save As Template" speichern zu können.
Alle Funktionen der -alten- "yabIDE" sind dabei erhalten geblieben, haben unter Umständen jedoch einen neuen Platz gefunden, sodass man sich die einzelnen Menüs einmal genauer ansehen sollte. Auch das Programm- Fenster wurde einer Modernisierung, wie in Bild 1 zu sehen, unterzogen.
Zugegeben, es funktioniert noch nicht alles wie es soll und so gibt es durchaus noch ein paar kleinere Baustellen, doch ich bin mir sicher, dass auch diese noch aus der Welt geschafft werden. Alles in Allem haben die Jungs von der "BeSly" jedoch hervorragende Arbeit geleistet und ich kann nur sagen weiter so.
Download
yab 1.7
yabConcept Creator
zurück zur Übersicht
yab - Prüfen ob "yab" installiert ist
Mittwoch, 19. September 2012
Zugegeben es klingt etwas seltsam wenn einer daherkommt und mit einem "yab"- Programm prüfen will ob "yab" installiert ist. Doch in einigen Fällen kann dies durchaus Sinn machen.
Bei meinen Experimenten mit dem "yabConceptCreator" ist mir aufgefallen, dass man Programme schreiben kann jedoch beim Ausführen in einen Fehler läuft wenn "yab" vorher nicht installiert wurde. Das Vorhandensein einer "yab"- Installation wird vom "ConceptCreator" also nicht überprüft. Da dieser aber ebenfalls in "yab" geschrieben wurde, könnte die untenstehende Sub- Routine dazu dienen diesen Notstand aus der Welt zu schaffen.
Die Sub- Routine gibt dabei die Werte "True", wenn "yab" gefunden wurde, bzw. "False" wenn "yab" nicht gefunden wurde, zurück. Der Quelltext ist wie immer mit reichlich Kommentaren versehen und sollte mit ein wenig "yab"- Erfahrung keine größere Herausforderung darstellen.
Beispiel
| import IsYabInstalled // Prüfen ob "yab" installiert ist if _IsYabInstalled() then // wenn ja ... print "yab ist installiert" else // wenn nein ... print "yab ist nicht installiert" endif |
Sub- Routine
| export sub _IsYabInstalled() // lokale Variablen- Definition local SystemInput$ // den Befehl "yab" über die Kommandozeile aufrufen und // das Ergebnis in SystemInput$ speichern SystemInput$ = system$("yab") // wenn das Ergebnis die Zeichenfolgen "yab" und "yabasic" enthält, // ist "yab" installiert if (instr(SystemInput$, "yab")) and (instr(SystemInput$, "yabasic")) then // wenn installiert, True zurüggeben return true else // wenn nicht installiert, False zurückgeben return false endif end sub |
yab - die "yab"- Version ermitteln
Samstag, 29. September 2012
Wie man das Vorhandensein einer "yab"- Installation überprüfen kann, habe ich ja bereits in einem meiner letzten Posts geschrieben. Heute möchte ich Euch eine Möglichkeit zeigen, wie man die Version des installierten "yab" ermitteln kann.
Wozu man dies brauchen kann, weis ich noch nicht so richtig, aber Verwendungszwecke gibt es ja recht viele, auch wenn mir im Moment keiner einfallen will. Für mich dient es mehr zum auffrischen meiner "yab"- Kenntnisse und Programmierfähigkeiten.
Das folgende kleine Beispiel mit der dazugehörigen Sub- Routine zeigt Euch einen möglichen Weg um an die gewünschte Information heran zu kommen. Wie immer sind die Quelltexte mit vielen Kommentaren versehen.
Beispiel
| import GetYabVersion print _GetYabVersion$() |
Sub- Routine
| export sub _GetYabVersion$() // lokale Variablen- Definition local SystemInput$ local Version$ local Position local Search$ // nach dieser Zeichenkette wird gesucht Search$ = "This is version" // den Befehl "yab" über die Kommandozeile aufrufen und // das Ergebnis in SystemInput$ speichern SystemInput$ = system$("yab") // ermittelt die Position an welcher die gesuchte Zeichenkette // beginnt Position = instr(SystemInput$, Search$) // ab dieser Position, zehn Zeichen prüfen for i = Position + len(Search$) to Position + len(Search$) + 10 // wenn das aktuelle Zeichen kein Leerzeichen (am Anfang) bzw. // kein Komma (am Ende) ist dann ... if (mid$(SystemInput$, i, 1) <> " ") and (mid$(SystemInput$, i, 1) <> ",") then // ... in Version$ speichern Version$ = Version$ + mid$(SystemInput$, i, 1) endif next // Ergebnis zurückgeben return Version$ end sub |
Scripting - Dateien "sicher" löschen
Mittwoch, 24. Oktober 2012
Nachdem Datensicherheit in der heutigen Zeit einen immer größeren Stellenwert bekommt, habe auch ich mir einmal Gedanken, zu diesem Thema, gemacht und meine Gedanken und Erfahrungen aufgeschrieben.
Thema dieses Artikels ist es, Dateien "sicher" zu löschen. Und beim Thema sicher löschen scheiden sich auch schon die Geister. Die einen sagen, es genügt völlig eine Datei einmal zu überschreiben, damit deren Inhalt nicht mehr wiederherzustellen ist. Die anderen sagen, eine Datei muss mindestens sieben Mal überschrieben werden um sicherzustellen das man den Inhalt nicht mehr wiederherstellen kann.
In diese Debatte möchte ich mich aber absolut nicht einmischen und jedem seinen Glauben lassen.
Nachdem ich mir nun Gedanken über das angesprochene Thema gemacht und ein paar Wege zum Erreichen dieses Ziels versucht habe, welche mehr oder weniger gefruchtet haben, bin ich im System von Haiku selbst über eine der praktikabelsten Lösungen gestolpert. Der Befehl heißt "shred" und er macht genau das, was wir wollen, nämlich Dateien beliebig oft und mit zufälligem Inhalt überschreiben.
Gibt man nun im Terminal einmal den entsprechenden Befehl ein, erscheinen, neben einigen hilfreichen Informationen, auch die folgenden Parameter und deren Verwendung.
| shred --help |
Diese Kommandozeilen- Schalter/Parameter sollten sich prinzipiell von selbst erklären.
Um das Ganze an einem Beispiel zu erklären, erzeugen wir uns zuerst eine Datei, welche wir dann per "shred"- Befehl auch wieder löschen können. Dabei können wir wie folgt vorgehen. Mit dem folgenden Befehl erstellen wir eine ca. 16 MB große Test- Datei.
| dd if=/dev/zero of=test.dd bs=16M count=1 |
Diese Datei überschreiben wir nun mit der Eingabe des folgenden Befehls. Dabei ist darauf zu achten, dass wir die Datei an dieser Stelle tatsächlich nur überschreiben jedoch nicht löschen.
| shred -f -n 5 -v -x test.dd |
Die Bedeutung der verwendeten Parameter ist dabei wie folgt:
- -f = erzwingt das Überschreiben der angegebenen Datei
- -n 5 = die Datei wird 5 Mal überschrieben
- -v = zeigt uns untenstehende Ausgabe
- -x = rundet die Datei- Größe nicht auf den nächsten vollen Block
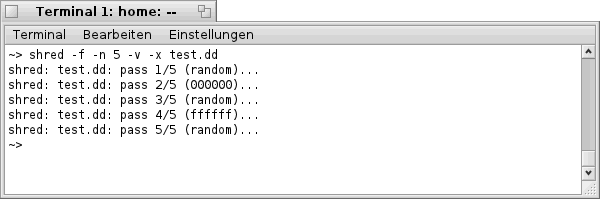
Ergänzt man nun die bereits oben verwendete Kommandozeile mit dem Parameter "-u", wird die angegebene Datei zusätzlich mehrfach umbenannt und anschließend gelöscht. Die Ausgabe sieht dann, wie im unteren Bild, aus.
| shred -f -n 5 -v -x -u test.dd |
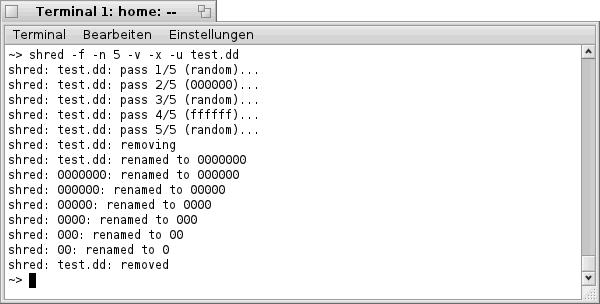
Schlussendlich kann man nun noch den Parameter "-z" hinzufügen, welcher die angegebene Datei noch ein letztes Mal mit Nullen überschreibt bevor sie endgültig gelöscht wird. Danach sieht die Ausgabe wie unten aus.
| shred -f -n 5 -v -x -u test.dd |
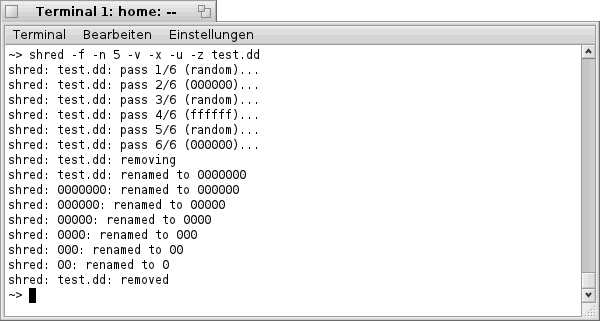
Wie im Bild zu sehen ist, wird zu den von uns eingestellten 5 Überschreib- Vorgängen ein 6ter hinzugefügt. Damit sollte die Datei genügend oft überschrieben und schließlich gelöscht worden sein. Auch das Umbenennen der Datei ist ein weiterer Pluspunkt, da sich so nicht mehr auf den eigentlichen Dateinamen schließen lassen sollte.
Mit dem Parameter "-n" sollte etwas pfleglich umgegangen werden, da man die Anzahl auch ins unermessliche erhöhen kann. Bei einem Test konnte ich eine Datei 5 Millionen Mal überschreiben, was natürlich nicht sinnvoll ist.
zurück zur Übersicht
Scripting - wir haben ein "date"
Samstag, 3. November 2012
Heute möchte ich wieder einmal einen kleinen Ausflug auf die Haiku- Kommandozeile unternehmen und Euch den recht unscheinbaren aber dennoch sehr mächtigen Befehl "date" ein wenig näher bringen.
Die Meisten werden jetzt denken, na toll wir können ein Datum auf der Kommandozeile ausgeben, damit ist es jedoch nicht getan, denn der "date"- Befehl bietet einiges mehr an Funktionen und mit der richtigen Formatierung kann man recht interessante Ausgaben bewerkstelligen.
Gibt man im Terminal lediglich den Befehl "date" ein, bekommt man folgende Ausgabe zu sehen.
| date |
Dies gibt uns die relativ kurze Information das heute Mittwoch der 31. Oktober 2012 ist und es 15:55:45 Uhr ist. Soweit recht unspektakulär aber informativ.
Ändert man nun den Aufruf für den "date"- Befehl entsprechend ab, kann die Ausgabe schon etwas eleganter gestaltet werden.
| date "+Datum: %d.%m.%Y%nUhrzeit: %H:%M:%S" |

Denkbar sind auch Ausgaben in der folgenden Form ohne Zeilenumbruch und mit deutlich mehr Text in der Ausgabe.
| date "+heute ist %A der %d. %B %Y, es ist jetzt %H:%M:%S Uhr" |
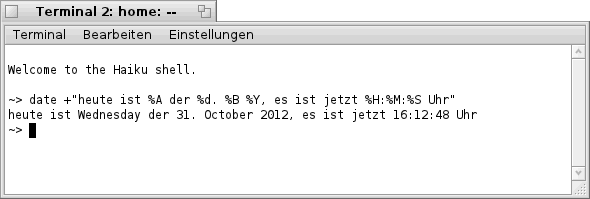
Leider übersetzt Haiku im Terminal die Tages- und Monats- Namen nicht, zumindest bei meiner "Alpha 3" nicht.
Aber mit dem "date"- Befehl lässt sich auch in die Vergangenheit oder die Zukunft blicken. So verrät uns der folgende Aufruf z.B. wann der nächste Mittwoch ist.
| date --date="next wednesday" "+naechster Mittwoch = %d. %B %Y" |
Anstelle von "next wednesday" kann man z.B. auch "yesterday" oder "tomorrow" angeben und erhält dann entweder das gestrige oder das morgige Datum. Außerdem können auch Werte wie "1 day ago" oder "10 days ago" eingegeben werden. Auch Werte wie "1 month" oder "1 year" werden akzeptiert.
Weiterhin kann man mit dem "date"- Befehl auch einen typischen Unix- Timestamp erzeugen indem man "date" mit dem Parameter "%s" aufruft. Dieser Timestamp gibt die Sekunden seit dem 01.01.1970 00.00.00 Uhr aus.
| date +%s |
Wie Ihr also sehen könnt, lässt sich der "date"- Befehl für eine ganze Reihe von Aufgaben einsetzen. Wer Lust und Laune hat kann gern ein wenig damit experimentieren. Mir bleibt nur noch zu sagen, viel Spaß.
zurück zur Übersicht
Scripting - Netzwerk und Co. (Teil 1)
Donnerstag, 22. November 2012
Nachdem ich mitbekommen habe das ich nicht der Einzige bin, bei dem das Netzwerk bzw. die Netzwerk- Karten unter Haiku hin und wieder das ein oder andere, seltsame Phänomen hervorzaubern, möchte ich heute von einigen dieser, mitunter seltsam wirkenden Dinge berichten und ein paar „Work- Arounds“ zeigen mit denen sich die ein oder andere Klippe umschiffen lässt.
Hin und wieder kann es vorkommen, dass Haiku eine Netzwerk- Karte vergisst. Dies kann sowohl die drahtlose als auch die Kabel- gebundene Karte betreffen. Eine Möglichkeit und die vergessene(n) Netzwerk- Karte wieder zu beleben erfordert ein Dual- Boot- System oder eine CD/DVD mit einem startbaren Betriebssystem welche die entsprechende(n) Netzwerk- Karte unterstützt. Getestet habe ich diese Vorgehensweise mit einem Dual- Boot- System auf welchem zusätzlich Windows 7 installiert ist und welche bisher immer einwandfrei funktioniert hat.
Sollte also einmal eine der vorhandenen und auch von Haiku unterstützten Netzwerk- Karten verschwunden sein, einfach neu Booten im Boot- Manager "Windows" wählen und selbiges starten. Nachdem Windows vollständig geladen wurde, einfach einen erneuten Restart durchführen und im Boot- Manager "Haiku" auswählen und starten. Danach sollte die vorher verschwundene Netzwerk- Karte wieder erscheinen. Warum dies so ist kann ich leider nicht sagen, aber wie bereits erwähnt hat diese Vorgehensweise bisher immer wunderbar funktioniert. Ob das Ganze auch mit einer Linux- Live- CD a'la Knoppix oder ähnlich, ebenfalls funktioniert habe ich bisher nicht Testen können, erscheint mir aber durchaus plausibel.
Sollte kein Dual- Boot- System oder keine Linux- Live- CD zur Verfügung stehen, oder Ihr keine Lust haben, zu warten bist Windows oder ein anderes Betriebssystem gestartet ist, könnte die folgenden Vorgehensweise ebenfalls zum Erfolg führen.
Als erstes sollte man ein "Terminal" starten und den Befehl
| ifconfig |
eingeben und mit der "Enter"- Taste bestätigen.
Als Ergebnis bekommt man alle aktuell zur Verfügung stehenden Netzwerk- Karten mit diversen Informationen aufgelistet (siehe Bild).
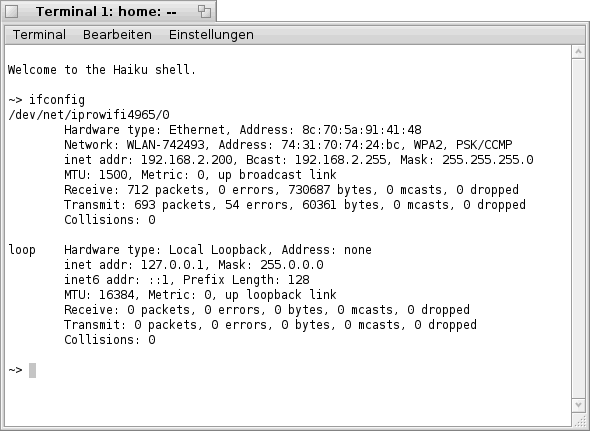
Ist man sich sicher das hier eine Netzwerk- Karte fehlt kann man die Gegenprobe mit Hilfe der folgenden Eingabe antreten. Im "Terminal" gibt man dazu den Befehl
| dir /dev/net |
ein und bekommt wiederum aufgelistet welche Netzwerk- Karten im System vorhanden und von Haiku erkannt und unterstützt werden (siehe Bild).
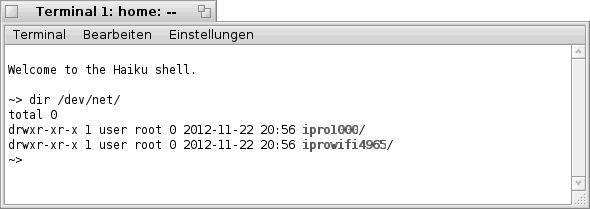
Wie im Beispiel zu sehen ist, ist die Ausgabe von "ifconfig" und "dir /dev/net" nicht identisch. Es fehlt die Netzwerk- Karte mit der Bezeichnung "ipro1000". Diese lässt sich nun mit folgendem Befehl wiederbeleben.
| ifconfig /dev/net/ipro1000/0 up |
Wenn wir nun erneut den Befehl "ifconfig" im "Terminal" eingeben, sollte die fehlende Netzwerk- Karte wieder sichtbar sein (siehe Bild).
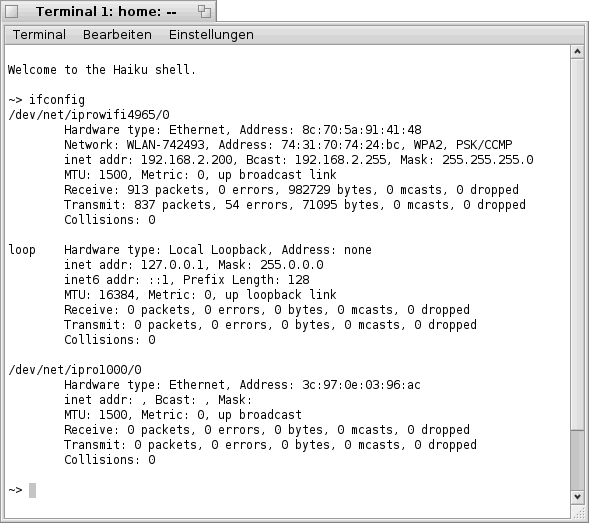
Abschließend besteht noch die Möglichkeit mit Hilfe des Befehls "listdev" herauszufinden welche Netzwerk- Karten im System vorhanden sind und von Haiku als solche erkannt wurden. Dies bedeutet jedoch nicht, dass diese auch von Haiku unterstützt werden. Nach Eingabe des Befehls
| listdev | grep -A 3 "device Network" |
im "Terminal" bekommt man die folgende bzw. eine ähnliche Liste zu sehen. Hier sind, wie bereits oben erwähnt, alle Netzwerk- Karten welche Haiku erkannt hat aufgelistet (siehe Bild).
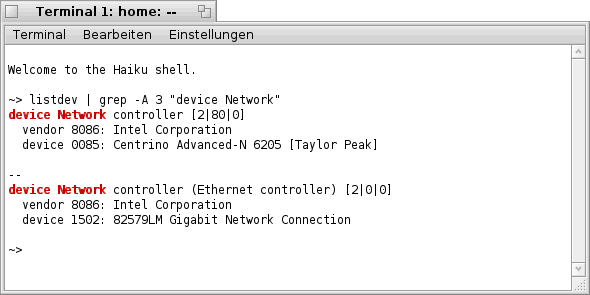
Ich hoffe das ich etwas dazu beitragen konnte das ein oder andere Netzwerk- Karten- Problem zu erkennen und vielleicht sogar zu lösen. Im nächsten Teil werde ich mich etwas mit "WLan", drahtlosen Netzwerk- Adaptern und der Verschlüsselung beschäftigen und hoffe auch damit das ein oder andere Problem aufzeigen und eventuell lösen zu können.
Viel Spaß.
zurück zur Übersicht
Scripting - Netzwerk und Co. (Teil 2)
Freitag, 7. Dezember 2012
So, nachdem nun (hoffentlich) alle Netzwerk- Karten gefunden wurden und ebenso (hoffentlich) ihren Dienst entsprechend verrichten, möchte ich Euch heute ein paar Stolpersteine auf dem Weg zum drahtlosen Netzwerk aufzeigen und eventuell zu deren Lösung beitragen.
Normalerweise würde man, um sich mit einem drahtlosen Netzwerk zu verbinden, das Netzwerk- Icon in der "Deskbar" mit der Mouse anklicken. So die drahtlose Netzwerk- Karte ihren Dienst entsprechend verrichtet wird man an dieser Stelle mit einer entsprechenden Liste aller erreichbaren drahtlosen Netzwerke belohnt (siehe Bild).
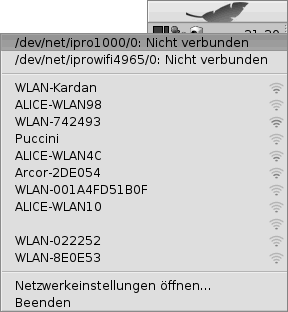
Wählt man nun das gewünschte Netzwerk aus der Liste mit einem Mouse- Klick aus, erscheint dabei folgendes Fenster (siehe Bild).
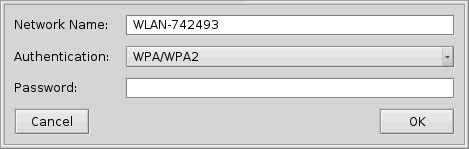
Im Feld "Network Name:" sollte der Name, also die SSID, des gewünschten Netzwerkes eingetragen sein. Über das Pulldown- Menü "Authentication:" könnt Ihr noch die Art der Verschlüsselung wählen und im Feld "Password:" müsst Ihr Euer WLan- Passwort eingeben. Diesen Dialog erhaltet Ihr ebenfalls wenn Ihr in der Liste aus "Bild 1" den Punkt "Netzwerkeinstellungen öffnen..." wählt und im nachfolgenden Fenster (siehe Bild), nachdem Ihr die entsprechenden Einstellungen gemacht hab, auf den Button "Anwenden" klickt.
Leider verfügt Haiku momentan noch nicht über die Möglichkeit das eingegebene Passwort dauerhaft zu speichern, sodass nach jedem Neustart des Systems dieses wieder von Hand eingegeben werden muss. Aber auch hierfür gibt es einen kleinen aber feinen Workaround.
Dazu öffnen wir ein "Terminal" und geben folgenden Befehl an der Kommandozeile ein.
| ifconfig /dev/net/iprowifi4965/0 join "WLAN- Name" PASSWORT |
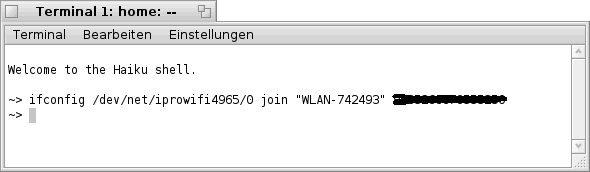
Oder Ihr packt das Ganze gleich in eine Script- Datei um nicht immer wieder alles abtippen zu müssen, denn der Befehl ist schließlich noch mehr Tipp- Arbeit als nun das WLan- Passwort. Ein entsprechendes Script könnte z.B. wie folgt aussehen.
| #!/bin/sh ifconfig /dev/net/iprowifi4965/0 join "WLAN- Name" PASSWORT |
Den Parameter "WLan- Name" ersetz Ihr dabei durch den Namen bzw. die SSID Eures drahtlosen Netzwerkes und den Parameter "PASSWORT" ersetzt Ihr mit Eurem WLan- Passwort. Anschließend das Script speichern und nicht vergessen das Flag für "Ausführen" zu setzen (siehe Bild).
Prinzipiell bietet es sich natürlich an, das oben erwähnte Script gleich in den Start- Vorgang zu integrieren um es nicht per Hand ausführen zu müssen. Leider habe ich jedoch feststellen müssen, das, wenn das Script zu früh gestartet wird, leider nichts passiert und das Netzwerk anschließend ebenfalls bzw. trotzdem nicht funktioniert. Wartet man jedoch ca. 3 - 4 Minuten nach dem Hochfahren und startet das Script dann per Hand (Doppelklick) funktionierte es bei mir jedes Mal einwandfrei. Aber vielleicht verhält sich Haiku auf Eurer Hardware ja auch anders als bei mir.
zurück zur Übersicht
yab - einen Splash- Screen implementieren
Mittwoch, 6. Februar 2013
Beim Starten von Programmen kann es, aus verschiedenen Gründen, durchaus einmal etwas länger dauern bis sich das Programm- Fenster öffnet. Dieses Verhalten kann die unterschiedlichsten Gründe haben.
Sei es das Laden von Icon- Grafiken, das Initialisieren von größeren Arrays, das Auslesen diverser Informationen, einfach nur um einen zu haben, etc., etc.
Um diese Wartezeit zu überbrücken, bzw. dem Benutzer zu zeigen, dass das Programm nicht im "Nirvana" verschwunden ist oder sich gar "aufgehängt" hat, kann man einen sogenannten Splash- Screen implementieren. Dieser kann dann, auf verschiedene Weise, dem Benutzer darüber Auskunft geben, was sich gerade abspielt oder womit das Programm im Moment beschäftigt ist.
Im Folgenden möchte ich Euch ein paar Beispiele zeigen wie man einen solchen Splash- Screen realisieren kann.
Als Grundlage der unten aufgeführten Beispiele dient die "yab"- Vorlage "Basic Template". Diese wird, wie Ihr sehen könnt ein wenig modifiziert. Fügt den Quelltext an der im Bild zu sehenden Stelle ein.
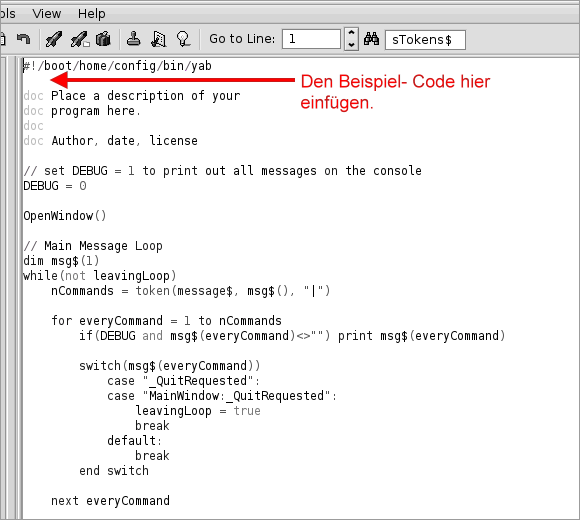
Beispiel 1 - Der einfache Weg.
Im ersten Beispiel wird ein einfaches Fenster, ohne Titel- Leiste und unveränderbar mit einem simplen Text angezeigt. Anschließend wartet das Fenster fünf Sekunden und schließt sich wieder. Anstelle der Pause (sleep) könnt ihr die verschiedensten Dinge erledigen, welche die Wartezeit verursachen. Sobald diese Aufgaben erledigt sind, schließt sich das Fenster ganz von allein wieder.
Quelltext
| // Splash- Screen implementieren (in der Bildschirm- Mitte) // ------------------------------------------------------------ // aktuelle Auflösung des Bildschirms auslesen SW = peek("desktopwidth") SH = peek("desktopheight") // die Größe des Fensters definieren WW = 400 WH = 200 // die X- und Y- Position des Fensters berechnen WPX = (SW / 2) - (WW / 2) WPY = (SH / 2) - (WH / 2) // das entsprechende Fenster öffnen window open WPX, WPY to WPX + WW, WPY + WH, "SplashWindow", "Splash- Screen" // das Fenster ohne Titel anzeigen window set "SplashWindow", "Look", "Modal" // damit das Fenster nicht verschoben und nicht verändert werden kann window set "SplashWindow", "Flags", "Not-Resizable, Not-Movable" // ein wenig Font- Spielerei draw set "DejaVu Sans, Bold, 36", "SplashWindow" // einen Titel mittig einblenden TW = draw get "Text-Width", "Splash- Screen", "SplashWindow" TH = draw get "Max-Text-Height", "SplashWindow" draw text (WW / 2) - (TW / 2), (WH / 2) + (TH / 2), "Splash- Screen", "SplashWindow" // einen Moment warten sleep 5 // An dieser Stelle können alle Arbeiten erledigt werden, welche den Programm- // Start verzögern. Wärend dieser Zeit wird der Splash- Screen angezeigt. // das Fenster wieder schließen window close "SplashWindow" |

Beispiel 2 - Der einfache Weg aber dynamischer.
Im zweiten Beispiel wird zusätzlich eine Statusbar mit angezeigt. Mit dieser kann man dem Benutzer zeigen, dass das Programm noch etwas macht und hat gleichzeitig eine Anzeige wie lange dies noch dauern könnte.
Quelltext
| // Splash- Screen implementieren (in der Bildschirm- Mitte) // ------------------------------------------------------------ // aktuelle Auflösung des Bildschirms auslesen SW = peek("desktopwidth") SH = peek("desktopheight") // die Größe des Fensters definieren WW = 400 WH = 200 // die X- und Y- Position des Fensters berechnen WPX = (SW / 2) - (WW / 2) WPY = (SH / 2) - (WH / 2) // das entsprechende Fenster öffnen window open WPX, WPY to WPX + WW, WPY + WH, "SplashWindow", "Splash- Screen" // das Fenster ohne Titel anzeigen window set "SplashWindow", "Look", "Modal" // damit das Fenster nicht verschoben und nicht verändert werden kann window set "SplashWindow", "Flags", "Not-Resizable, Not-Movable" // ein wenig Font- Spielerei draw set "DejaVu Sans, Bold, 36", "SplashWindow" // einen Titel mittig einblenden TW = draw get "Text-Width", "Splash- Screen", "SplashWindow" TH = draw get "Max-Text-Height", "SplashWindow" draw text (WW / 2) - (TW / 2), (WH / 2) + (TH / 2), "Splash- Screen", "SplashWindow" // eine Status- Bar für den Fortschritt anzeigen statusbar 20, 150 to WW - 20, 180, "SplashStatus", "", "", "SplashWindow" // oder in mehreren Schritten // An dieser Stelle können alle Arbeiten erledigt werden, welche den Programm- // Start verzögern. Wärend dieser Zeit wird der Splash- Screen angezeigt. // Schritt 1 statusbar set "SplashStatus", "", "", 20 sleep 1 // Schritt 2 statusbar set "SplashStatus", "", "", 40 sleep 1 // Schritt 3 statusbar set "SplashStatus", "", "", 60 sleep 1 // Schritt 4 statusbar set "SplashStatus", "", "", 80 sleep 1 // Schritt 5 statusbar set "SplashStatus", "", "", 100 sleep 1 // das Fenster wieder schließen window close "SplashWindow" |

Beispiel 2 - Der einfache Weg aber dynamischer.
Beispiel 3 - Auch einfach aber schöner.
Im dritten Beispiel bauen wir den Quelltext etwas um und zeigen eine Grafik an. Damit aber nicht genug. Um den Eindruck zu erwecken, dass unsere Grafik überhaupt kein Fenster ist, erstellen wir zuerst einen Screenshot vom Fensterhintergrund und laden diesen als Bild in unser Fenster. Anschließend zeigen wir darüber unsere eigene Grafik an. Dank der Unterstützung von "*.png"- Grafiken, wird diese ohne Hintergrund und wenn vorhanden mit entsprechender Transparenz angezeigt (siehe Bild unten).
Quelltext
| // Splash- Screen implementieren (in der Bildschirm- Mitte) // ------------------------------------------------------------ // aktuelle Auflösung des Bildschirms auslesen SW = peek("desktopwidth") SH = peek("desktopheight") // die Größe des Fensters definieren WW = 300 WH = 290 // die X- und Y- Position des Fensters berechnen WPX = (SW / 2) - (WW / 2) WPY = (SH / 2) - (WH / 2) // den Hintergrund unter dem Fenster speichern screenshot WPX, WPY to WPX + WW + 1, WPY + WH + 1, Bitmap$ // das entsprechende Fenster öffnen window open WPX, WPY to WPX + WW, WPY + WH, "SplashWindow", "Splash- Screen" // das Fenster ohne Titel anzeigen window set "SplashWindow", "Look", "No-Border" // damit das Fenster nicht verschoben und nicht verändert werden kann window set "SplashWindow", "Flags", "Not-Resizable, Not-Movable" // den gespeicherten Hintergrund wieder anzeigen draw bitmap 0, 0, Bitmap$, "Copy", "SplashWindow" // ein Bild anzeigen err = draw image 0, 0, "/boot/home/SplashScreen.png", "SplashWindow" // einen Moment warten // An dieser Stelle können alle Arbeiten erledigt werden, welche den Programm- // Start verzögern. Wärend dieser Zeit wird der Splash- Screen angezeigt. sleep 5 // das Fenster wieder schließen window close "SplashWindow" |

Ich hoffe ich konnte Euch mit diesem Thema ein paar Anregungen liefern und wünsche allen die es gern ausprobieren wollen viel Spaß.
zurück zur Übersicht
yab - Tooltips mehrzeilig ausgeben
Freitag, 3. Mai 2013
Tooltips sind ein feine Sache, sofern man sie in vernüftigem Umfang und an den richtigen Stellen einsetzt. Sie können wertvolle Hinweise aus die zu wählende Funktion enthalten oder auch nur eine kurze Erklärung.
In machen Situationen wäre es jedoch von Vorteil auch mal einen längeren Text auszugeben. Dies funktioniert auch wunderbar, doch leider ist am Bildschirmrand Schluß und mal ganz ehrlich, so ewig lange Zeilen will doch auch keiner lesen.
Mit einem kleinen Trick kann man den Text eines Tooltip aber auch in mehrere Zeilen aufteilen, was der Lesbarkeit durchaus zuträglich ist. Die Vorgehensweise ist dabei recht einfach. Man teilt den, zu langen, String in kleinere Portionen auf und hängt am Ende jedes einzelnen Teil- Strings einfach ein "chr$(10)" an (Beispiel 1). Alternativ dazu kann man auch ein "\n" anhängen (Beispiel 2), welches den selben Effekt erzielt. Das folgende kleine Beispiel zeigt dies.
Als Ausgangspunkt nutzen wir einfach das "Basic Template" und fügen in der Sub- Routine "OpenWindow", direkt nach dem Befehl "window open ..." die folgende Zeilen ein.
Beispiel 1
| Text$ = "Zeile 1" + chr$(10) Text$ = Text$ + "Zeile 2" + chr$(10) Text$ = Text$ + "Zeile 3" + chr$(10) Text$ = Text$ + "Zeile 4" + chr$(10) Text$ = Text$ + "Zeile 5" tooltip "MainWindow", Text$ |
Beispiel 2
| Text$ = "Zeile 1 \n" Text$ = Text$ + "Zeile 2 \n" Text$ = Text$ + "Zeile 3 \n" Text$ = Text$ + "Zeile 4 \n" Text$ = Text$ + "Zeile 5" tooltip "MainWindow", Text$ |
Startet man nun das abgeänderte Script, sollte man, sobald der Mouse- Zeiger über dem Fenster ist, einen mehrzeiligen Tooltip sehen können (siehe Bild).
Scriptiing - Externe IP- Adresse ermitteln
Mittwoch, 17. September 2014
Ab und an kann es vorkommen das man seine externe IP- Adresse, also die mit welcher man sich im Internet bewegt, herausbekommen muss/will. Um dies zu bewerkstelligen kann man sich z.B. einer der folgenden URL's bedienen und sich diese im Browser anzeigen lassen. Beispiele für solche Seiten sind:
- http://www.wieistmeineip.de
- http://www.whatismyip.com
- http://centralops.net/co/
- http://www.speedtest.net
Hier kann man sich nun, aus den mehr oder weniger bunten Seiten, seine IP- Adresse heraussuchen. Dies ist im Prinzip auch schon alles. Doch was macht man wenn man diese IP- Adresse weiterverarbeiten will?
Ganz einfach, man bedient sich einiger weniger Systemfunktionen, welche man von der Kommandozeile aus aufrufen kann. Dazu bedient man sich zuerst des Befehls "wget" welcher mit ein paar Parametern verfeinert wird. Im folgenden Bespiel holt man sich eine der erforderlichen Seiten per "wget" und speichert diese temporär auf der Festplatte.
| wget -o log -O dummy http://centralops.net/co/body |
Mit dem Parameter "-o" wird eine Ausgabe der verschiedensten Meldungen am Bildschirm unterdrückt, diese wandern stattdessen in die Datei "log" (sehr hilfreich wenn man das Ganze in einem Script verwenden will).
Der Parameter "-O" erzeugt eine Datei mit dem viel sagenden Namen "dummy" in welcher der HTML- Code der angeforderten Seite gespeichert wird.
Zum Schluss muss natürlich noch die URL der entsprechenden Seite angegeben werden. In diesem Beispiel verwenden wir die Seite von "centralops".
Nachdem wir nun den HTML- Code temporär gespeichert haben, können wir uns diesen, z.B. mit "cat", ansehen. Mit der Eingabe von...
| cat dummy |
...wird der gesamte Inhalt der Datei am Bildschirm ausgegeben. In diesem, mehr oder weniger, grossem Wust an HTML- Code verbirgt sich irgendwo die Information auf die wir es abgesehen haben, aber wo?
An dieser Stelle hilft uns, wieder einmal, der befehl "grep" weiter. Mit diesem können wir unsere Suche nach der gewünschten Information schon einmal erheblich einschränken. Im angegebenen Beispiel, also der Seite von "centralops", steht vor der gesuchten Information z.B. ein "addr=". Dieser String taucht sonst nirgendwo weiter auf. Also machen wir uns dies zu nutze und filtern die Ausgabe mit "grep" und dem gesuchten String.
| cat dummy | grep "addr=" |
In der Ausgabe können wir nun schon die gewünschte Information, relativ deutlich, erkennen. Aber das ist uns natürlich noch nicht genug. Wir müssen das Ergebnis noch weiter filtern um ausschließlich die benötigte IP- Adresse zu bekommen. Dies können wir mit dem Befehl "awk" bewerkstelligen und ergänzen die Kommando Zeile um folgende Befehle:
| cat dummy | grep "addr=" | awk '{ print $4 }' | awk -F">" '{ print $1 }' | awk -F"=" '{ print $6 }' | grep -oE "\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b" |
Das Ergebnis dieser, doch recht langen, Befehlskette ist die gesuchte Information und nur diese. Fragt mich bitte nicht wie das mit dem "Pattern" funktioniert, das habe ich selbst nur "gegoogled". Aber es funktioniert. Man muß das Rad ja nicht immer wieder neu erfinden.
Verwendet man eine andere Web- Seite, müssen die Befehle etwas angepasst werden. Man muss sich also die Seite wenigstens einmal als HTML- Code ansehen um Anhaltspunkte für das Filtern zu finden. Ich habe Euch noch zwei Bespiele mit angehängt, die ihren Dienst, zumindest bei mir, einwandfrei verrichten.
Es kann natürlich auch sein, dass eine Web- Seite die Informationen nicht so einfach preis gibt, das das Ganze z.B. mit Java- Script oder ähnlichen Sprachen umgesetzt wurde, oder man die richtige URL nicht finden kann. Das ist aber nicht weiter dramatisch, denn es gibt genügend Alternativen.
Beispiel 1 - "centralops.net"
| #!/bin/sh echo external ip address via "centralops.net" echo -------------------------------------- # get centralops website wget -o log -O dummy http://centralops.net/co/body # grep information cat dummy | grep "addr=" | awk '{ print $4 }' | awk -F">" '{ print $1 }' | awk -F"=" '{ print $6 }' | grep -oE "\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25 [0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b" # delete temporary files rm dummy rm log |
Beispiel 2 - "wieistmeineip.de"
| #!/bin/sh echo external ip address via "wieistmeineip.de" echo -------------------------------------- # get wieistmeineip.de website wget -o log -O dummy http://www.wieistmeineip.de # grep information cat dummy | grep -A 2 "Ihre IP-Adresse lautet:" | awk '{ print $2 }' | awk -F">" '{ print $3 }' | grep -oE "\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?\.){3}(25[0- 5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b" # delete temporary files rm dummy rm log |
Getestet wurde dies alles mit Haiku - 47865 und natürlich einer funktionierenden Internet- Verbindung.
zurück zur Übersicht
Anleitung erstellt durch René Passier (Chaotic) 2011-2014
Bereitgestellt durch BeSly, der Haiku Wissensbasis.